模型
Presto 是 Facebook 开源的 MPP (Massive Parallel Processing) SQL 引擎,其理念来源于一个叫 Volcano 的并行数据库,该数据库提出了一个并行执行 SQL 的模型,核心思想就是 Operator Model 和 Iterator Model。
- Operator Model
即通过各种 Operator 组成一棵树,树的根节点负责结果输出,树的叶子节点是各种 TableScan。这棵树被称作 Plan(执行计划),数据库里又被细分为逻辑执行计划和物理执行计划。这棵树是由 SQL 经过词法、语法分析及语义分析后,生成一个 AST(Abstract Syntax Tree),一般经过 Visitor 模式遍历后生成。原始数据通过叶子节点 TableScan 读取数据,然后经过各个 Operator的计算,包括(TableScan、Project、Filter、Exchange、Agg、Join、TaskOutput等)产出结果。 - Iterator Model
顾名思义就是一个递归迭代过程,Plan 树的各节点有三个状态,Open、GetNext及Close。从根节点 Open 开始递归调用 GetNext 获取数据,即父节点递归调用子节点接口直到没有结果为止,然后Close。
概念
Stage
MPP的理念就是能尽量细粒度的将 SQL 并行执行,以一个 SQL 2个表 JOIN 后 Agg 为例,那么每个表都可以单独并行执行去 Scan 数据(互不影响),然后进行 Join 和 Agg。所以执行计划(Plan)将执行 PlanFragment,即将一个树分块变为各个子树,每个子树可以并行的在多台机器上执行,这个 Fragment 被称为 Stage。
Presto根据 Stage 的用途,分为四种stage:
- Coordinator_Only:一般表示 DDL,DML 的 Stage
- Single:用于聚合子 stages 数据,并最终将数据输出给终端用户。比如每个查询中的根节点(Root Stage)
- Fixed:用于接收子 Stage 产生的数据,并在集群中对这些数据进行聚合或分组计算
- Source:连接数据源,从数据源读取数据
我们以简单的SQL查询为例,SQL为select id from table limit 1; 这个SQL简单来说,就干了2件事,一是Scan数据,另外是Limit,而这2件事,可以并行执行,所以如图所示,其分为2个Stage: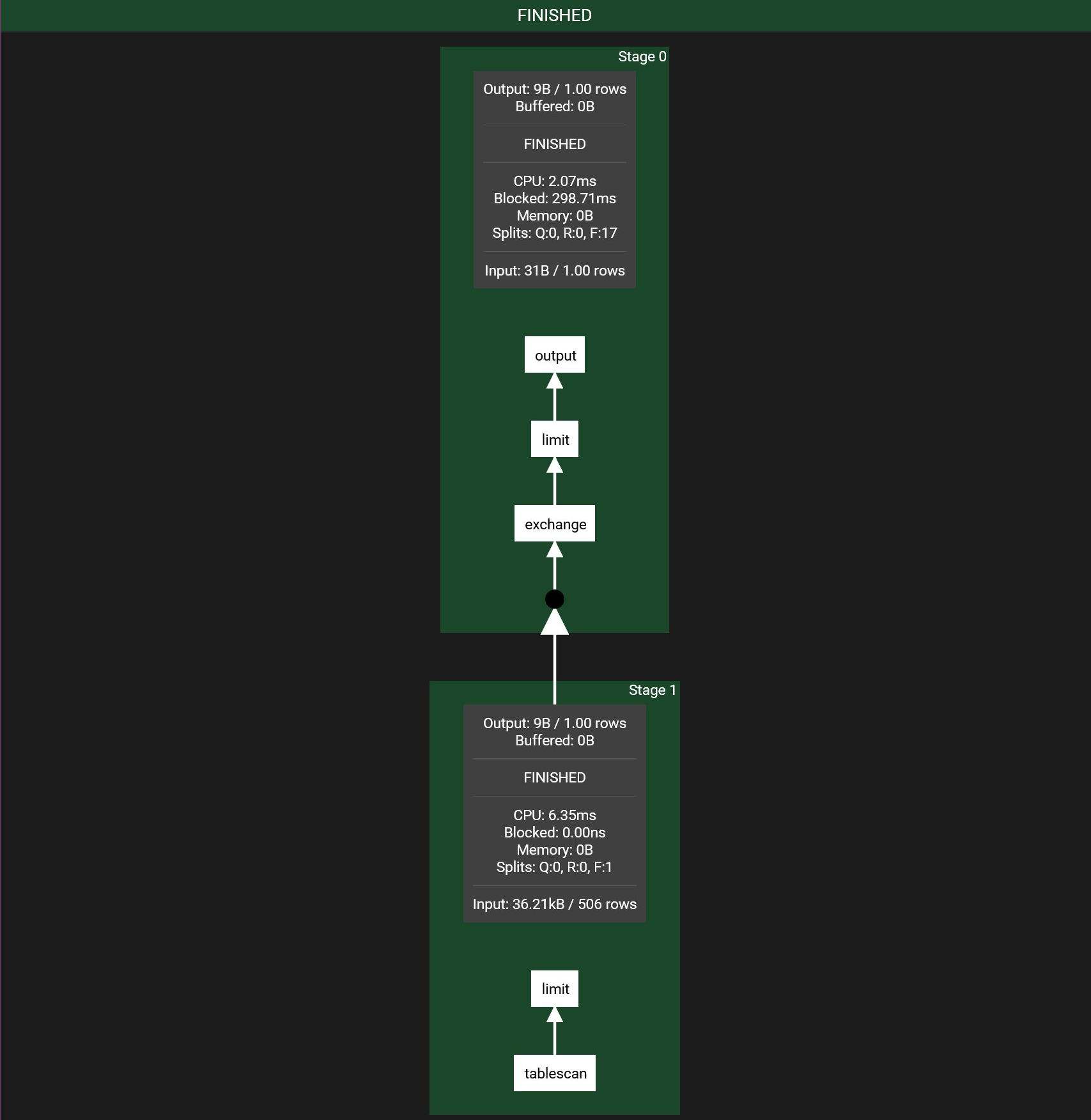
Stage 1 为Scan数据和Limit,这里Limit是下推优化。Stage 0为最终结果输出。
同时Presto UI里可以看到每个Stage详细信息,以及每个Stage需要的Task数(可以认为Worker数),如图所示: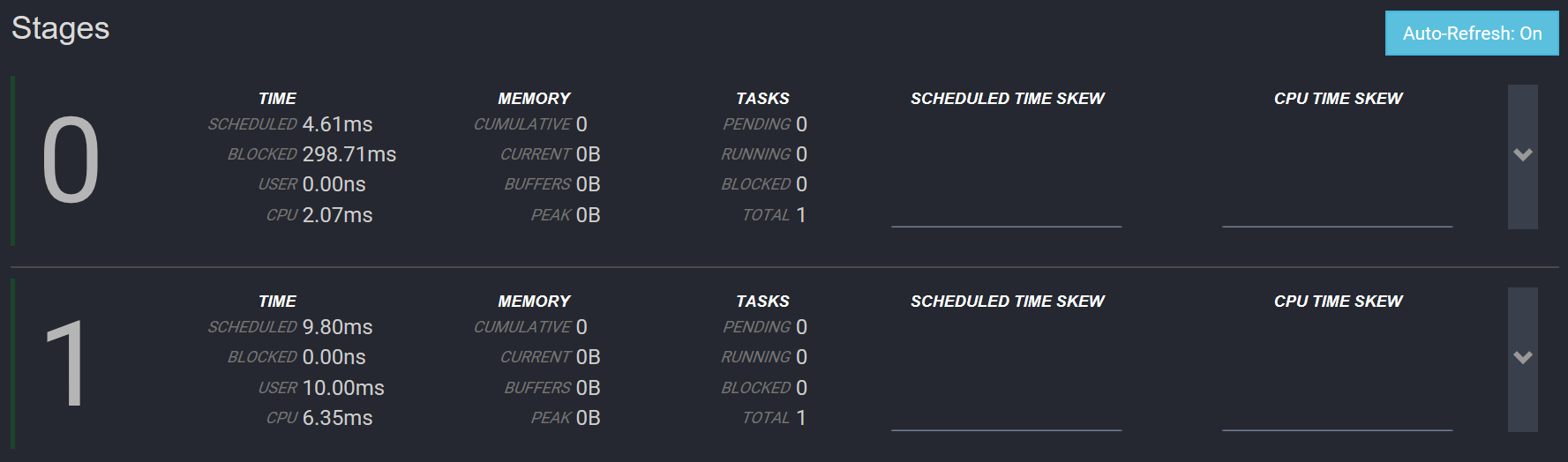
Exchange
连接不同的 Stage,用于不同 Stage 之间的数据交互。数据的交互有一些Operator实现,比如数据是Hash分发还是完全Replicate等。从上图可以看到Stage 1 和Stage 0 需要交互,通过Exchange实现。
Task
Stage 有多个 Task 组成。Stage 并不会运行,其实个抽象的概念,其只是负责管理 Task 和封装建模。Stage 实际运行的是Task。每个Task处理一个或者多个Split,每个Task被分配到每台机器上执行。每个Task都有对应的输入和输出。同一个Stage下的Task是个并行的概念,做的事情是相同的。
如下图所示,我们可以看到每个Tasks的相信信息,其中0.x表示Stage 0,1.x表示Stage 1,同时我们也可以看到每个Task执行花费的时间,读取的数据大小以及每个Task处理的Split数目。一个Stage包含一个或多个Task,每个Task做的事情是一样的,所以每个Stage的花费时间由最慢的Task决定,比如Scan HDFS数据,可能会因为某些Data Node阻塞导致Task阻塞。
Driver
Task 被分解成一个或者多个 Driver,并行执行多个 Driver 的方式来实现 Task 的并行执行。Driver 是作用于一个 Split 的一系列 Operator 的集合。一个 Driver 处理一个 Split,产生输出由 Task 收集并传递给下游的 Stage 中的一个 Task。一个 Driver 拥有一个输入和输出。
Operator
Operator 表示对一个 Split 的一种操作。比如过滤、转换等。 一个 Operator 一次读取一个 Split 的数据,将 Operator 所表示的计算、操作作用于 Split 的数据上,产生输出。每个 Operator 会以 Page 为最小处理单位分别读取输入数据和产生输出数据。Operator 每次只读取一个 Page,输出产生一个 Page。
Split
一个分片表示大的数据集合中的一个小子集,与 MapReduce 中的 Split 概念类似。对于Hive中的表,一个Split就是HDFS文件的一个分片。根据文件格式是否分片(如ORC,Parquet),该Split可能是一个Block的大小,也可能是整个文件。
Page
Presto 中处理的最小数据单元。一个 Page 对象包括多个 Block 对象,而每个 Block 对象是一个字节数组,存储一个字段的若干行。多个 Block 的横切的一行表示真实的一行数据。一个 Page 最大 1MB,最多 16 * 1024 行数据
Pipeline
Stage 里有很多 Operator,这些 Operator 可能并行度是不一样的,比如 Scan 数据并行就很大,但是最后聚合数据,并行一般为1。所以 PlanFragment 又会被切分为若干 Pipeline,每个 Pipeline 由一组 Operator 组成,这些 Operator 被设置同样的并行度。Pipeline 之间会通过 LocalExchangeOperator 来传递数据。
在 Presto UI 上我们可以看到 Pipeline信息,如下图所示,Stage 0 主要是将 Exchange 的数据,做最后的 limit,所以其可以细分为 2 个步骤,LocalExchangeOperator 及 LimitOperator,这2个动作的并行度是不一样的,Exchange 可以多个线程去做,而 Limit 只需要一个线程。从图中我们可以看到 Driver 和 Operator 信息,其中 Driver 的数目就是这个 Pipeline 的并行度。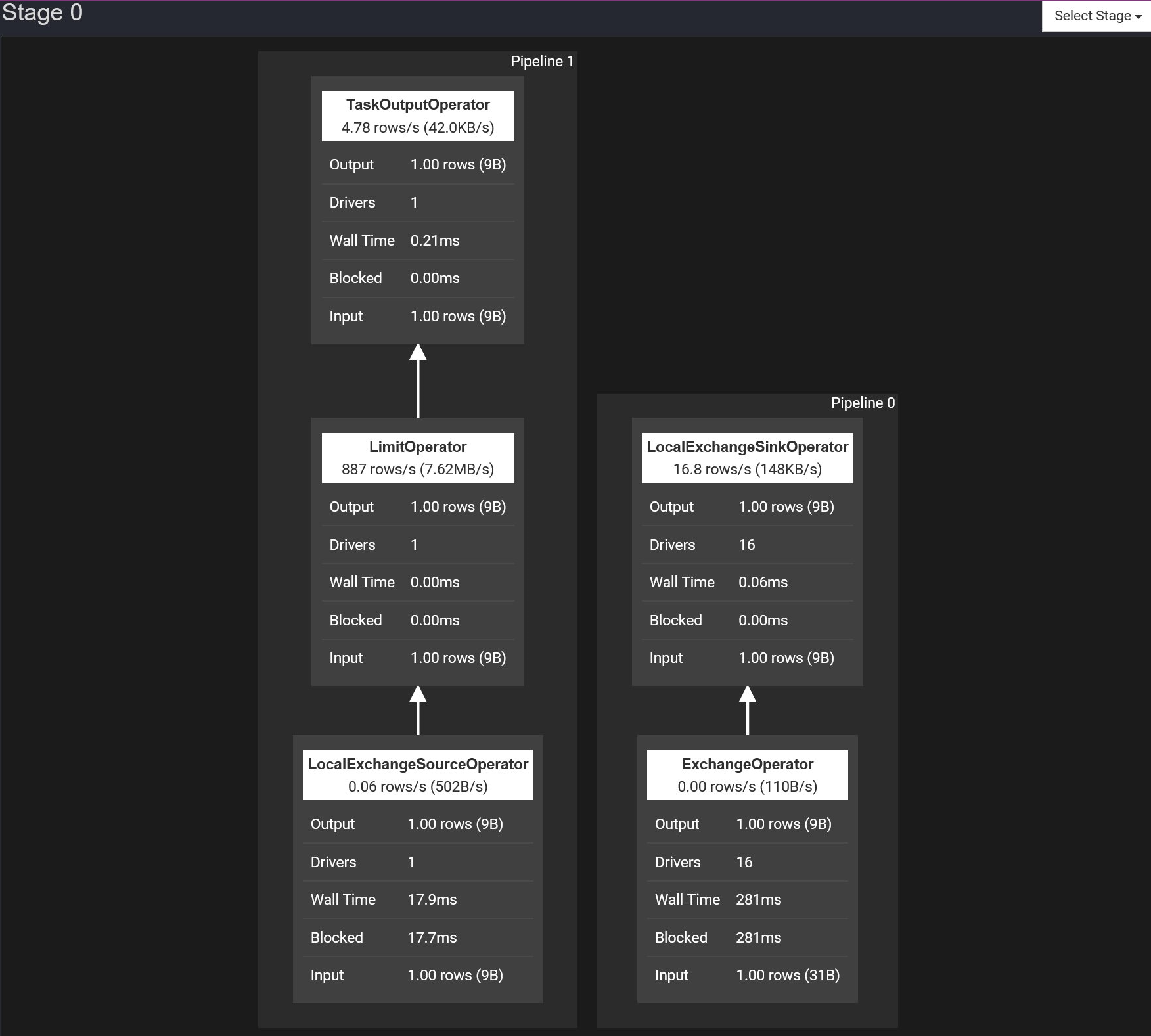
因为后续会陆续介绍 Presto 的一些执行流程,为了防止被一些概念绕晕,所以本文主要是对 Presto 的一些概念和专有名词做了一些科普和解释。
参考资料
- 《Presto技术内幕》
- 《Presto基本概念》