简介
ORC的全称是(Optimized Row Columnar),其是为了加速Hive查询以及节省Hadoop磁盘空间而生的,其使用列式存储,支持多种文件压缩方式。由于其被广泛应用在Hadoop系统中,Presto 0.77版本在Hive Connector里实现了ORC Reader。
ORC文件结构
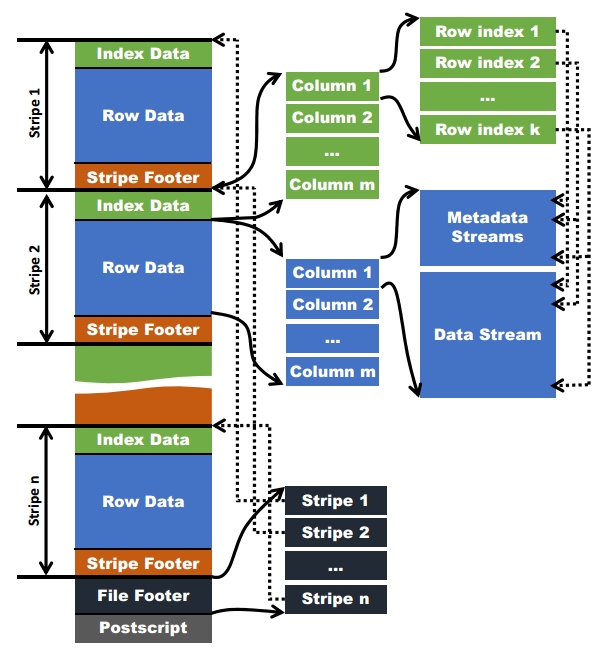
上图(图1)来自网络,有很多文章通过这张图片介绍了ORC文件结构,我这里就不多啰嗦了,我们直接通过数据来看文件格式吧。
创建表
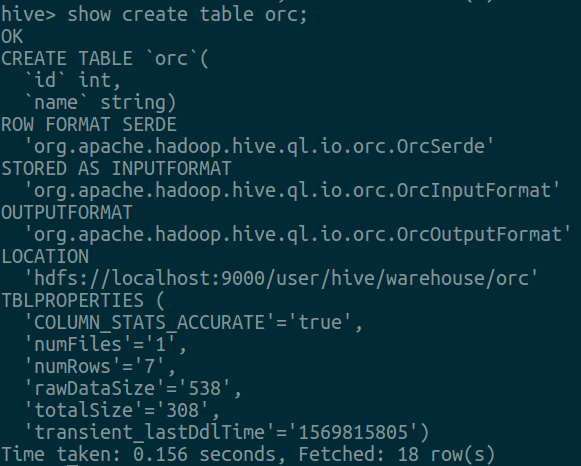
插入数据
1 | insert into orc(id,name) values(1,'a'),(2,'b'),(3,'c'),(4,'d'),(5,'e'),(6,'f'),(7,null); |
注:我们想只生成一个文件,所以一次插入了7条数据,否则会生成多个文件,不利于我们后续分析。
Dump数据
使用Hive自带的ORC DUMP工具,命令:
1 | ./bin/hive --orcfiledump hdfs://localhost:9000/user/hive/warehouse/orc/000000_0 |
数据格式: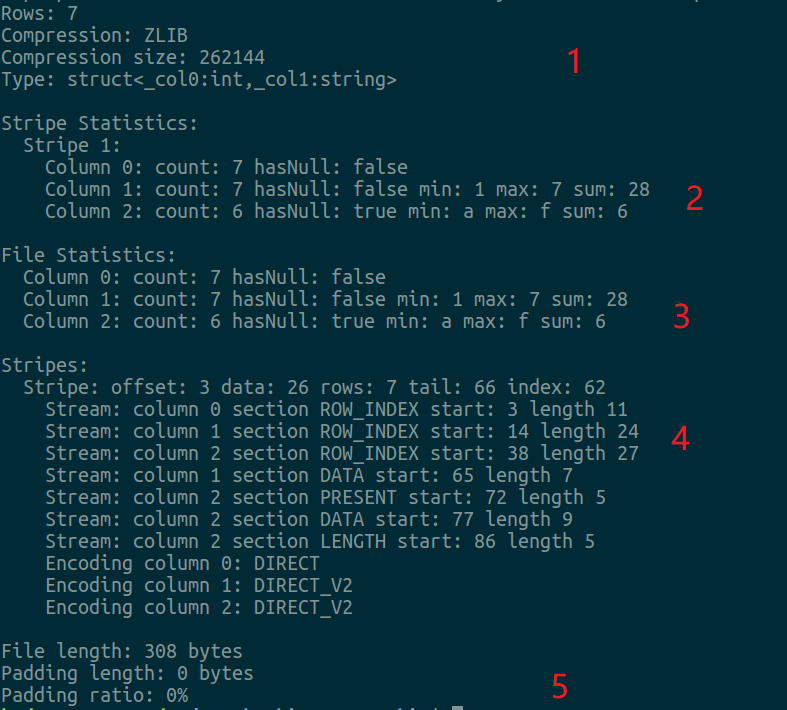
上图由回车划分了5个模块,第五个模块表示该ORC文件数据大小,我们不需要关心。
- 模块1
对应图1里面的PostScript,包含压缩类型及表结构信息 - 模块2
Stripe Statistics对应图1里面的Stripe Footer,Stripe粒度的索引,可以看到其包含3列,Column 1 对应id字段,包含其最大值和最小值以及包含其sum总和,其中也有个hasNull标记,用于标记是否含有NULL,此字段可用于SQL里带有is null的优化,Column 2对应name字段,与Column 1相似,但是sum表示非NULL值的行数。注意此处只含有1个Stripe,默认为10000,参数hive.exec.orc.default.row.index.stride可控制其大小,简单测试了下,发现此值最小为1000,否则生成MR出错,具体需要代码里再确认下。Column 0只统计其count值,可以忽略。 - 模块3
对应图1里面的File Footer,与Stripe Footer相似,但是是文件级别的索引。 - 模块4
stripe详细信息,就是真实列数据块,其中又分为Index data(记录每列的索引信息),Raw Data(记录原始数据),Index data可以根据自身业务特点做些性能调优,比如实现布隆过滤器索引(Hive 1.2实现)。Raw Data是通过row group保存的,其实可以简单的认为就是默认按照10000将原始数据划分更小的块,每一个row group由多个stream保存数据和索引信息。每一个stream的数据会根据该列的类型使用特定的压缩算法保存。在ORC中存在如下几种stream类型: - PRESENT:每一个成员值在这个stream中保持一位(bit)用于标识该值是否为NULL
- DATA:当前stripe的成员值,真实数据
- LENGTH:每一个成员的长度,string类型特有,否则你不知道每个string的长度
- DICTIONARY_DATA:对string类型数据编码之后字典的内容
- SECONDARY:存储Decimal、timestamp类型的小数或者纳秒数等
通过模块4,我们可以看到id含列有DATA Stream,而name含有PRESENT、DATA、LENGTH Stream,因为存在空值,所以多了个PRESENT Stream。
Presto ORC及优化
Presto在实现ORC时,Hive-based ORC reader维护的数据是行式的,Presto想使用官方提供的客户端时还需要将行数据转换为列数据,且当时不支持Predicate pushdown,所以索性Presto自己实现ORC Reader,不过Hive 0.13也实现了VectorizedOrcRecordReader提供列格式。
Predicate pushdown
由ORC文件格式分析,ORC在每个文件中提供三级索引:
- 文件级别,整个文件级别的统计信息
- stripe级别,每个stripe每列中的值的统计信息
- 行级别 (行组),stripe中每组10000行(默认值)的每列值的统计信息
假如查询过滤条件为WHERE id = 1,首先从文件的统计信息(一级索引)中看看id字段的min/max值,如果1不包含在内,那么跳过该文件;如果在这个文件中,那么继续查看二级索引,每个stripe中id字段的min/max值,如果1不包含在内,那么跳过此stripe;如果在该stripe中,则继续匹配row group中的min/max值(三级索引),如果1不包含在内,那么跳过该row group。如果1包含在内min和max范围内,则利用布隆过滤器再次判断是否一定不在内,不在内则继续跳过该行组。其原理就是通过三级索引,将查询范围缩小到10000行的集合,而原始数据是列式存储,更加适合CPU pipeline的编码方式,有效利用这种局部性,缓存可以达到极高的命中率,所以ORC有非常高效的性能。
Lazy reads
以SQL为例,SELECT a, b FROM ... WHERE a = ...,如果a不匹配,那么将不会读取b的列。
Bulk reads
Presto老版本ORC Reader代码可以简化为以下逻辑:
1 | if (dataStream == null) { |
比如float及double的datatStream.next()实现为:
1 | public float next() |
一次只读取一个值,将其改为按照Bulk loading(比如8*SIZE_OF_FLOAT),读取性能有明显提升。
而对于Boolean reader,之前一次处理 1 bit数据(但是读取按照Byte),优化点是将其改为一次处理 8 bit(1 Byte)。
Improve null reading
从上面的代码可以看到,当有PRESENT Stream时(就是存在null值时),还要每次处理PRESENT Stream,读取DATA Stream及 PRESENT Stream,CPU Cache利用率很低,所以上面代码改为了下面形式:
1 | // bulk read and count null values |
先将数据读取临时文件里,然后依次处理。
Avoid dynamic dispatch in loops
1 | for (int i = 0; i < nextBatchSize; i++) { |
很多Stream Reader只包含一种type,但是LongStreamReader会包含BIGINT、INTEGER、SMALLINT、TINYINT 及 DATE Types。这会让JVM的一些优化失效,比如inline,改动为:
1 | if (type instanceof BigintType) { |
因为早期Hive ORC Reader的一些特性,导致Presto自己实现了ORC Reader,但是现在来看,直接调用社区的ORC Reader效果会更好,因为Presto基本上每2、3个小版本就会修复ORC Bug或者做些简单的性能提升,但是代码里很多都是来源于社区ORC的代码,Presto社区整体进展缓慢,直接调用社区ORC接口,省下了优化和修复Bug的时间,剩下的时间做些Presto引擎更核心的事情应该才是正确的做法。