背景
之前介绍过Presto内存管理和分配策略,但是那个是0.192版本,详细见:Presto内存管理原理和调优 ,0.201之后内存管理作了新的修改,所以重新简单分析下,然后给出一个配置模板,希望对使用Presto的同学有帮助。
两种内存
Presto里面内存只有2种内存,一种是user memory,另一种是system memory。system memory用于input/output/exchange buffers等,user memory 用于hash join、agg这些。
内存池
0.201之前有3种内存POOL,分别是GENERAL_POOL、RESERVED_POOL及SYSTEM_POOL。但是0.201之后,默认SYSTEM_POOL是不开启的,以下参数控制,默认值为false
1 | deprecated.legacy-system-pool-enabled |
那SYSTEM_POOL不使用了,这块内存怎么控制呢,去代码里确认了下:
SqlTaskManager#createQueryContext
1 | private QueryContext createQueryContext( |
可以看到systemPool.get()被替换为了localMemoryManager.getGeneralPool(),所以GENERAL_POOL扮演了之前GENERAL_POOL及SYSTEM_POOL的作用,提供user memory和system memory。
说完SYSTEM_POOL,再说下RESERVED_POOL,RESERVED_POOL作用就是当GENERAL_POOL满的时候,将最占用内存的SQL分配到这块内存上来,但是实际使用时,这块内存很少会被使用,原因是,
一般使用Presto的业务是用来SQL提速的,不会使用spill disk功能,第二为了服务的稳定性,会限制最大内存和Kill内存策略,所以会出现查询没有被分配到RESERVED_POOL之前,
SQL将会被系统Kill掉。第三是大查询一般会用Spark/Hive替代,所以这块RESERVED_POOL就会浪费掉了,如下图所示:
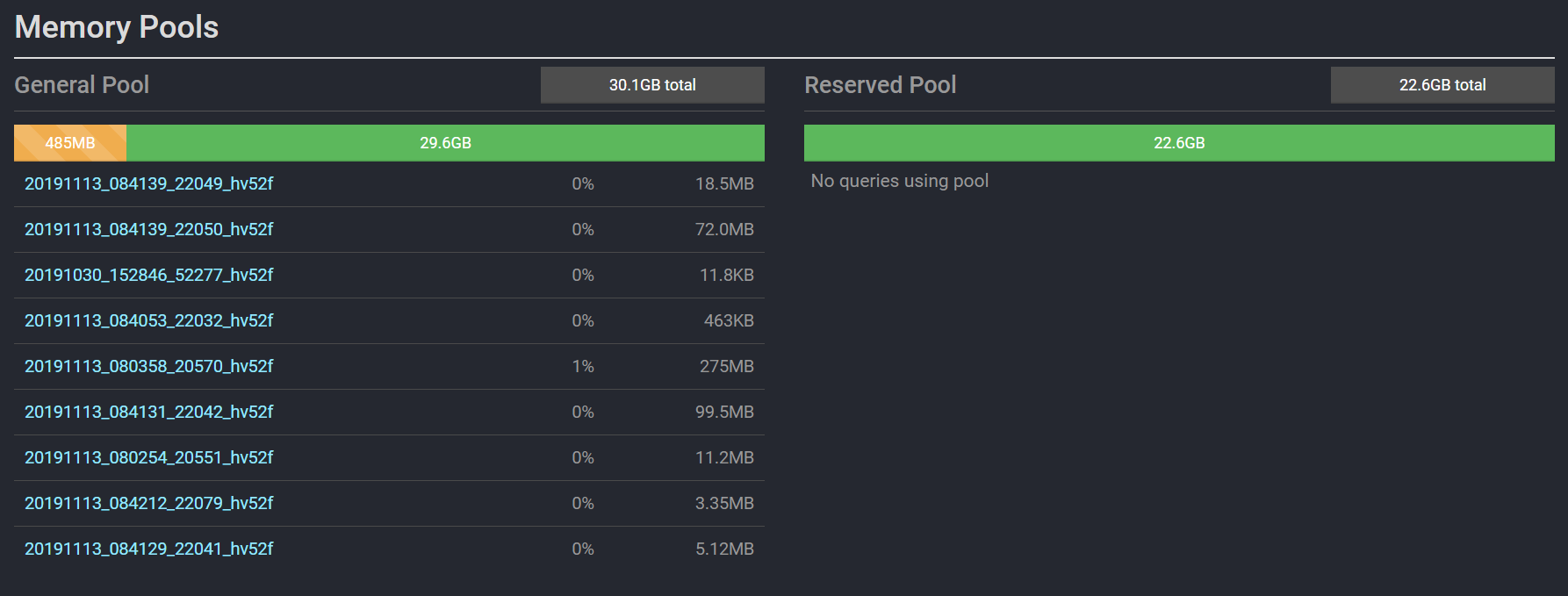
目前有9个SQL正在查询,都在使用GENERAL_POOL,RESERVED_POOL将会浪费掉。所以对于绝大部分Presto使用者,禁止掉RESERVED_POOL是正确的选择。
新的参数
1 | memory.heap-headroom-per-node |
这个内存主要是第三方库的内存分配,无法被统计跟踪,默认值是XMX*0.3。
所以,Presto内存分配只需要考虑GENERAL_POOL及heap-headroom-per-node。
分配方法
既然Presto是一个纯内存OLAP引擎,那肯定不能让查询占用的内存无限大,需要参数控制SQL占用的最大内存,Presto内存管理包括了单机和集群粒度的内存,分别是:
- query.max-memory-per-node: 单个Query在单个Worker上允许的最大user memory
- query.max-total-memory-per-node: 单个Query在单个Worker上允许的最大user memory + system memory
- query.max-memory: 单个Query在整个集群上允许的最大user memory
- query.max-total-memory: 单个Query在整个集群上允许占用的最大user + system memory
而集群query.max-memory由query.initial-hash-partitions控制,现在默认值为100,但是这个值受限于Worker个数,即值为min(100,Worker Nums)。老版本的默认值为8, 所以我一般还是用8来计算的,那query.max-memroy 一般稍小于query.max-memory-per-node*8即可(考虑到数据倾斜)。
根据代码和上面分析知道:
RESERVED_POOL = query.max-total-memory-per-node
所以新的
GENERAL_POOL = TotalMemory - ReservedPool - memory.heap-headroom-per-node
禁止掉RESERVED_POOL时:
GENERAL_POOL= TotalMemory - memory.heap-headroom-per-node
配置
综上,Presto合适的内存分配配置为如下,假如-Xmx80G,Worker数大于8台:
1 | query.max-memory=120GB # 默认为20GB,query.max-memory-per-node * 8 * 0.8 ,倾斜按照0.8算即可 |
比如上面分配后,GENERAL_POOL为80GB - 16GB = 64GB,如下图所示,RESERVED_POOL不再存在。query.max-total-memory默认值为2*query.max-memory,这个参数可以保持默认值即可。
