背景
最近Presto集群又上线了几个新业务,伴之而来的是OOM很频繁,且发生时间多在早晨8点左右,线上稳定性是高优需要解决的,所以查找了下导致Presto集群OOM的原因,发现了一些问题,这里抛砖引玉下,可能其他使用Presto的用户也会遇到类似的问题。
排查过程
我给一些业务划分了不同的label,这里说明下我们把Presto引擎改进了下,可以动态将机器划分不同的label,这样SQL查询时候指定不同的label,SQL调度时只根据指定的label查找机器即可。之后发现一个业务方的SQL会导致集群OOM。具体表现为,多次Full GC,之后OOM,看GC日志第一感觉应该是有内存泄露。
我通过审计日志(之前通过event-listener实现了个日志审计模块)拿到OOM时2K左右条SQL,发现SQL都是简单的SQL,类似这种:
1 | SELECT * FROM table WHERE year='2020' AND month='06' AND day='01' LIMIT 10; |
根据SQL,我猜测可能以下2种原因导致了OOM:
- 查询的表存在Hive视图(我让Presto支持了Hive视图)
- 异常SQL触发了内存泄露
因为这个业务方的SQL都是小查询,90时间也就1S样子,所以懒得推测原因了,直接把SQL拿到,二分法测试环境跑一遍SQL,通过jstat -gcutil查看GC情况,Old区飙升的会认为存在潜在问题,最终定位了6个表有问题,并且在查询这些表SQL时,Old区疯涨,然后Full GC,连续多次Full GC后OOM。
show create table 查看下表字段信息,70-100个左右字段,但惊奇的发现这几个表都是ORC格式,所以OOM与ORC有关系吗?
那通过orcdump查看下这些orc的元信息吧,命令:
1 | ./bin/hive --orcfiledump hdfs://localhost:9000/user/hive/warehouse/orc/000000_0 |
惊奇的发现这个ORC文件竟然有2W+个Stripe Statistics,猜测是Stripe Statistics太大导致的问题,如下图所示: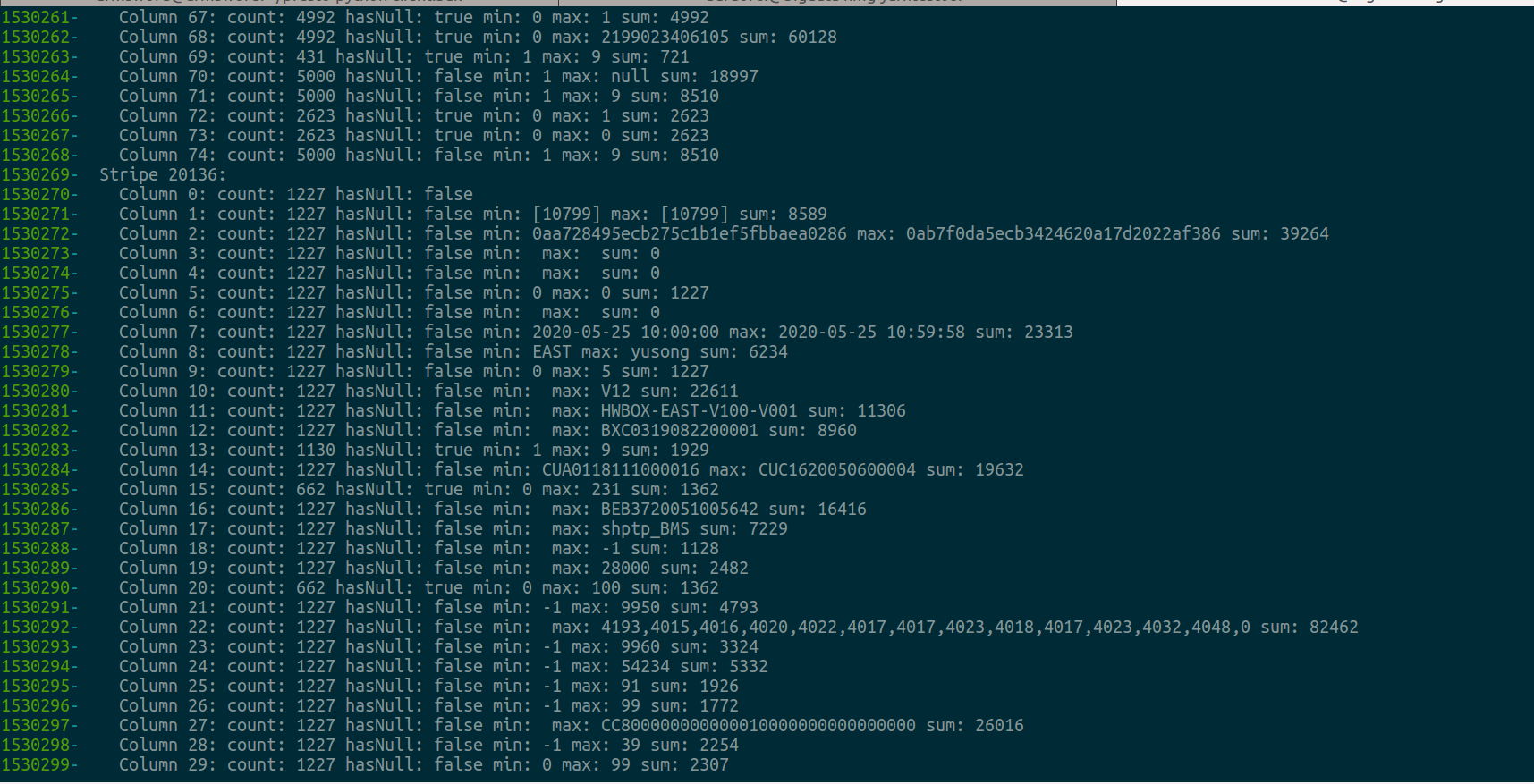
第一反应,是不是用户生成orc参数配置错了,比如stripe的大小设置过小,但是看了下业务方的生成orc的参数,属于正常的,如下图: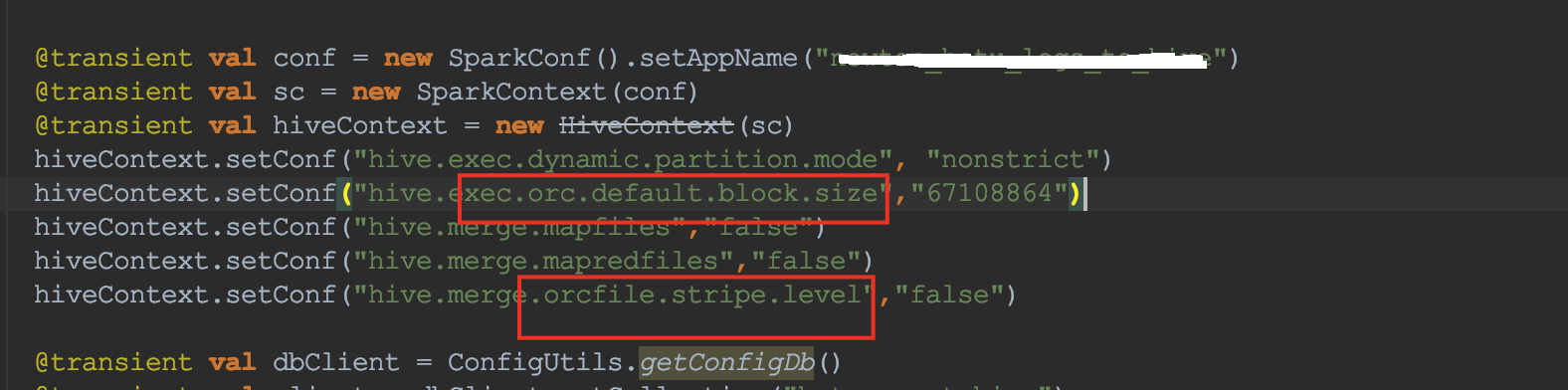
hadoop du看了下orc文件,发现一个表只有一个orc文件,且竟然大于20GB,根据orc predicate pushdown的先后顺序策略:
- 文件级别,整个文件级别的统计信息
- stripe级别,每个stripe每列中的值的统计信息
- 行级别 (行组),stripe中每组10000行(默认值)的每列值的统计信息
那文件的大小应该会影响stripe的大小,于是让业务方将repartition改为10,即生成10个文件,测试发现查询小于1S,且无OOM。
验证成功,即Orc Stripe Statistics太大导致的问题。那为什么Stripe Statistics太大会导致Presto OOM呢?
我们测试环境查询一个有问题的SQL,然后perf下,看下火山图,看下当时Presto当时都在做什么,如下图所示: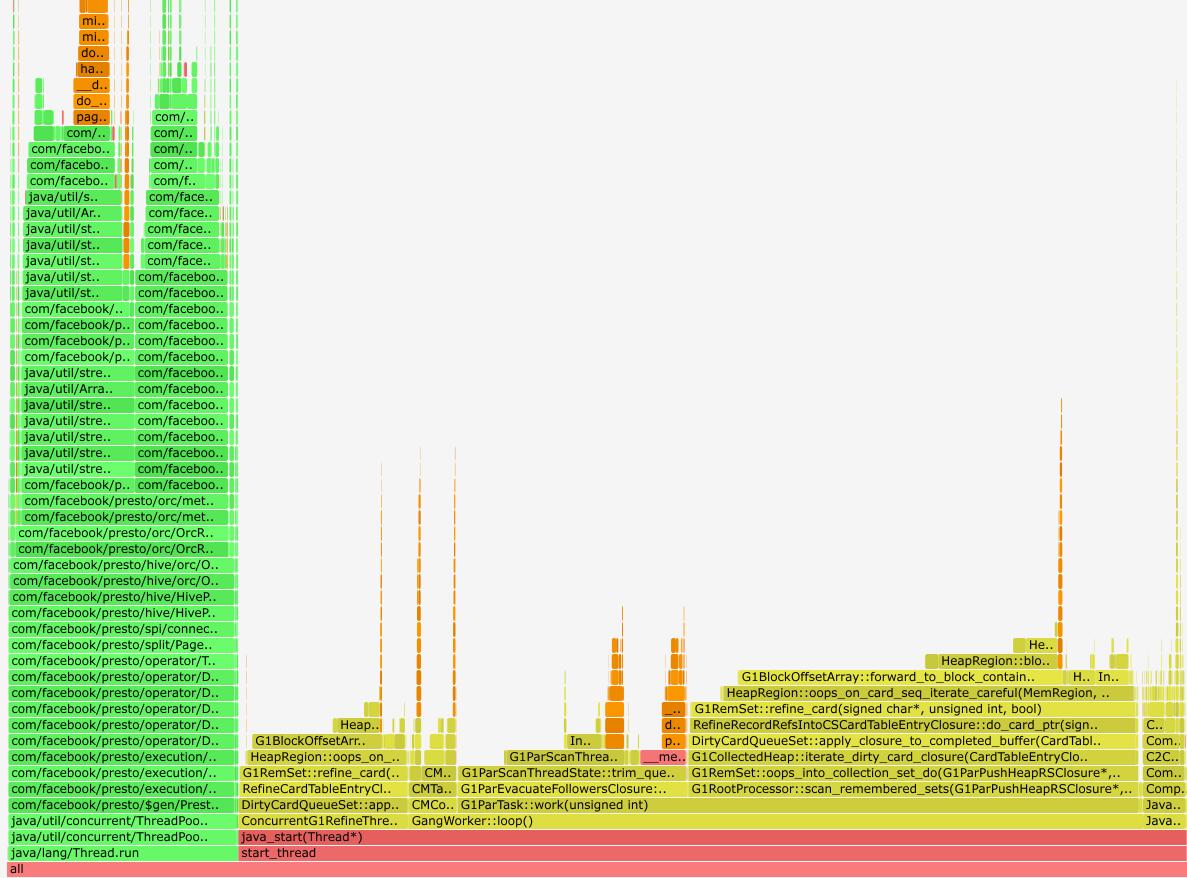
发现大约70%的CPU都用于GC,剩下的都在执行SQL计算。我们生成一份CPU采样,看下执行SQL计算时主要做什么,如下图: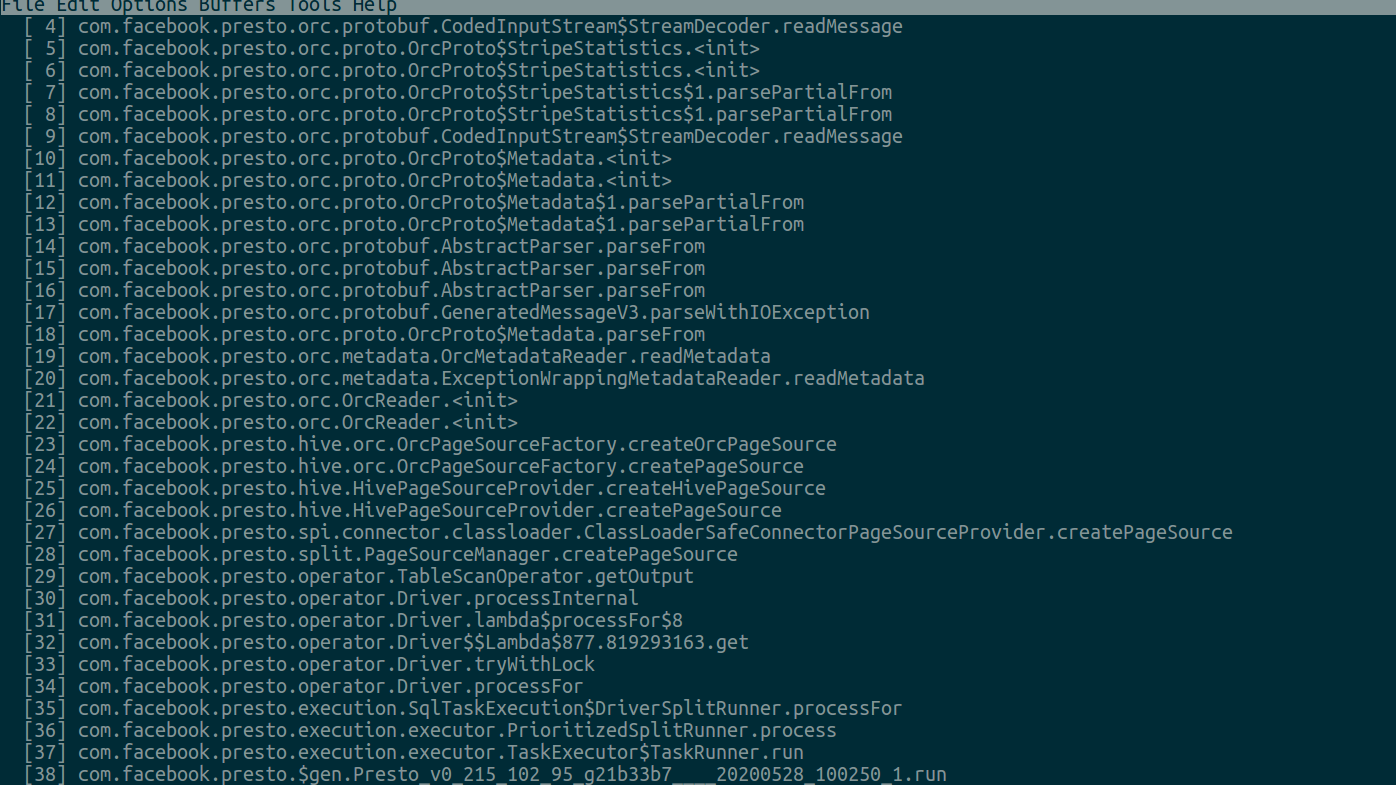
根据上图可以看到每个Driver对应的split都在读取Stripe Statistics,我们的猜测是符合预期的,所以原因就明朗了:
业务方使用spark产出orc文件,其repartition设置为1,就会产生一个大于20+G的orc文件,导致stripe个数太多,比如产生2W个stripe(有些表orcdump都不成功,stripe statistics太大了,无法dump,远超2W个),假如表有75个字段,那就会产生2W * 75 个实例,如果presto再划分多个split,比如100,那就是100 * 2W * 75 个instance,因为这个内存是untracked memory,无法使用Presto的OOM Killer逻辑,如果机器内存比较小,那可能2个sql就导致oom了。
引擎改进
我们通知了业务方如果ORC文件太大,将ORC拆分为多个文件,但是可能业务方比较多,下次依然遇到类似的问题,所以引擎需要改进下,尽量让这种不符合预期的SQL直接报错。我们知道ORC使用Protocol buffers来定义一个orc file中元数据的结构,PB报文是限制大小的,网上搜索了下是64MB,但是为什么Presto依然能查询报文超过64MB的ORC文件?研究了下,发现CodedInputStream有个setSizeLimit接口可以限制PB报文的大小,我将其改为64MB,发现有问题的SQL将会查询失败,符合预期。
但是我发现一个问题,当报文超过64M,SQL查询失败后,worker old区依然快满了,我jmap触发了full gc,old区没有任何变化,说明有类似内存泄露的问题,但是过了15分钟后,old区恢复正常,我们知道task info会在内存里保留15分钟,难道与这个有关?于是我dump了份内存,使用MAT分析了下。
如下图所示,发现Stripe Statistics依然在内存中:
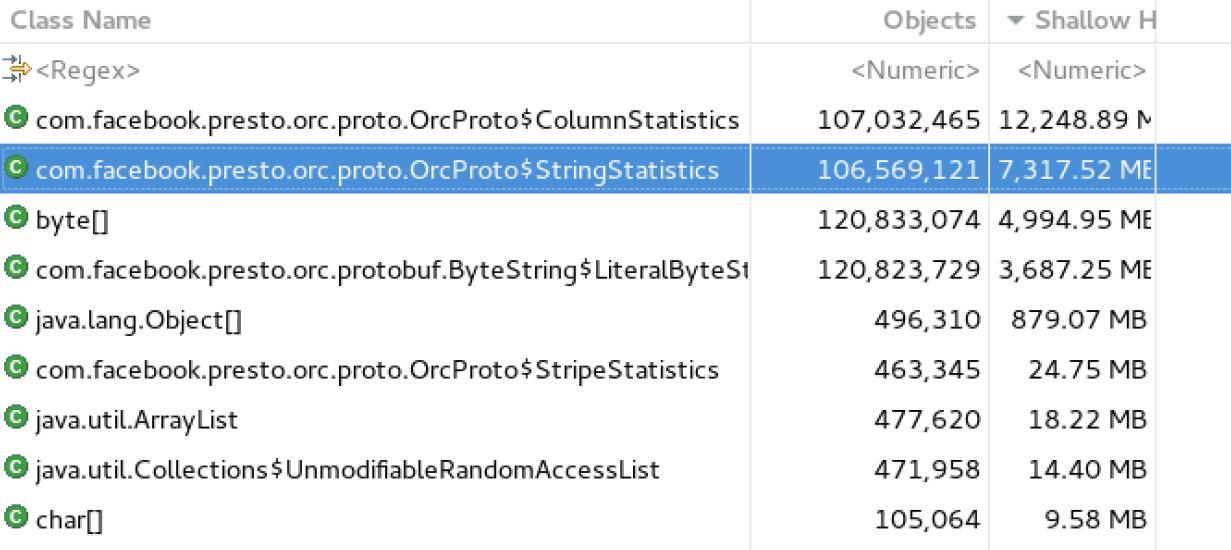
看下哪里引用了这些类,导致无法被内存释放,如下图所示:
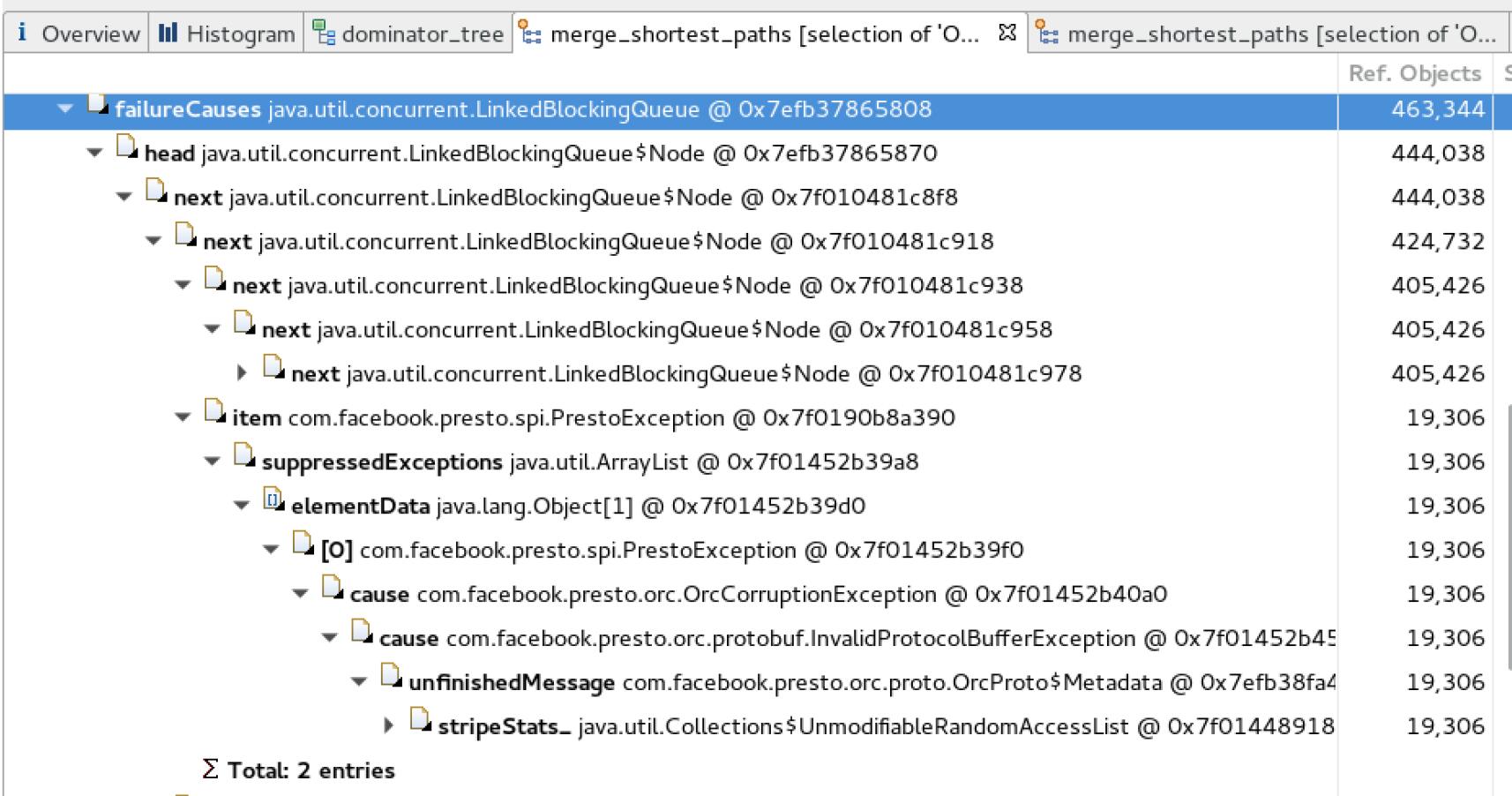
这样就明白了,读取ORC文件失败时候,每个split都抛出了异常,然后异常信息扔入一个链表里,每个异常信息竟然引用了Orc Statistics信息。既然原因明了了,我们将异常信息替换下,这样就避免了Stripe Statistics信息被引用导致无法被释放,简单修改下代码测试下:
1 |
|
之后测试,查询超过64MB报文的ORC文件,查询失败,无内存泄露产生,世界终于清净了。