Presto 简介
简介
Presto是Facebook 开源的 MPP (Massive Parallel Processing) SQL 引擎,其理念来源于一个叫 Volcano 的并行数据库,该数据库提出了一个并行执行 SQL 的模型,它被设计为用来专门进行高速、实时的数据分析。Presto是一个SQL计算引擎,分离计算层和存储层,其不存储数据,通过Connector SPI实现对各种数据源(Storage)的访问。
架构
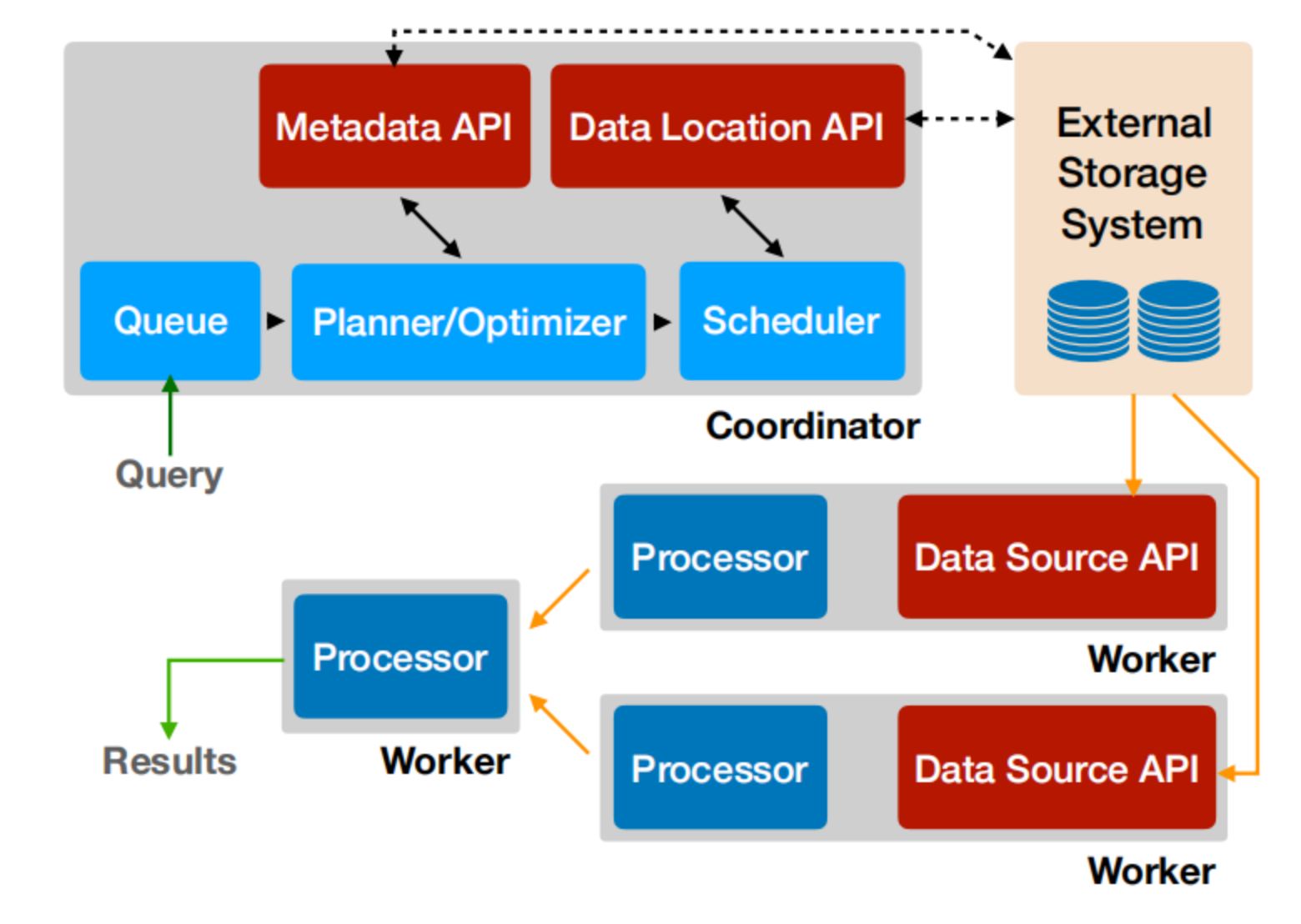
Presto沿用了通用的Master-Slave架构,一个Coordinator,多个Worker。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行;Worker节点负责实际执行查询任务。Presto提供了一套Connector接口,用于读取元信息和原始数据,Presto 内置有多种数据源,如 Hive、MySQL、Kudu、Kafka 等。同时,Presto 的扩展机制允许自定义 Connector,从而实现对定制数据源的查询。假如配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点通过Hive Connector与HDFS交互,读取原始数据。
实现低延时原理
Presto是一个交互式查询引擎,我们最关心的是Presto实现低延时查询的原理,以下几点是其性能脱颖而出的主要原因。
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- GC控制
- 无容错
Presto 在滴滴的应用
业务场景
- Hive SQL查询加速
- 数据平台Ad-Hoc查询
- 报表(BI报表、自定义报表)
- 活动营销
- 数据质量检测
- 资产管理
- 固定数据产品

业务规模

业务增长

集群部署

目前Presto分为混合集群和高性能集群,如上图所示,混合集群共用HDFS集群,与离线Hadoop大集群混合部署,为了防止集群内大查询影响小查询, 而单独搭建集群会导致集群太多,维护成本太高,我们通过指定Label来做到物理集群隔离(详细后文会讲到)。而高性能集群,HDFS是单独部署的,且可以访问Druid, 使Presto 具备查询实时数据和离线数据能力。
接入方式
- 二次开发了JDBC、Go、Python、Cli、R、NodeJs 、HTTP等多种接入方式,打通了公司内部权限体系,让业务方方便快捷的接入 Presto 的,满足了业务方多种技术栈的接入需求。
- Presto 接入了查询路由 Gateway,Gateway会智能选择合适的引擎,用户查询优先请求Presto,如果查询失败,会使用Spark查询,如果依然失败,最后会请求Hive。在Gateway层,我们做了一些优化来区分大查询、中查询及小查询,对于查询时间小于3分钟的,我们即认为适合Presto查询,比如通过HBO(基于历史的统计信息)及JOIN数量来区分查询大小,架构图见:

引擎迭代

我们从2017年09月份开始调研Presto,经历过0.192、0.215,共发布56次版本。而在19年初(0.215版本是社区分家版本),Presto社区分家,分为两个项目,叫PrestoDB和PrestoSQL,两者都成立了自己的基金会。我们决定升级到PrestoSQL 最新版本(340版本)原因是:
- PrestoSQL社区活跃度更高,PR和用户问题能够及时回复
- PrestoDB主要主力还是Facebook维护,以其内部需求为主
- PrestoDB未来方向主要是ETL相关的,我们有Spark兜底,ETL功能依赖Spark、Hive
引擎改进
在滴滴内部,Presto主要用于Ad-Hoc查询及Hive SQL查询加速,为了方便用户能尽快将SQL迁移到Presto引擎上,且提高Presto引擎查询性能,我们对Presto做了大量二次开发。同时,因为使用Gateway,即使SQL查询出错,SQL也会转发到Spark及Hive上,所以我们没有使用Presto的Spill to Disk功能。这样一个纯内存SQL引擎在使用过程中会遇到很多稳定问题,我们在解决这些问题时,也积累了很多经验,下面将一一介绍:
1、Hive SQL兼容
18年上半年,Presto刚起步,滴滴内部很多用户不愿意迁移业务,主要是因为Presto是ANSI SQL,与HiveQL差距较大,且查询结果也会出现结果不一致问题,迁移成本比较高,为了方便Hive用户能顺利迁移业务,我们对Presto做了Hive SQL兼容。而在技术选型时,我们没有在Presto上层,即没有在Gateway这层做SQL兼容,主要是因为开发量较大,且UDF相关的开发和转换成本太高,另外就是需要多做一次SQL解析,查询性能会受到影响,同时增加了Hive Metastore的请求次数,当时Hive Metastore的压力比较大,考虑到成本和稳定性,我们最后选择在Presto引擎层上兼容。
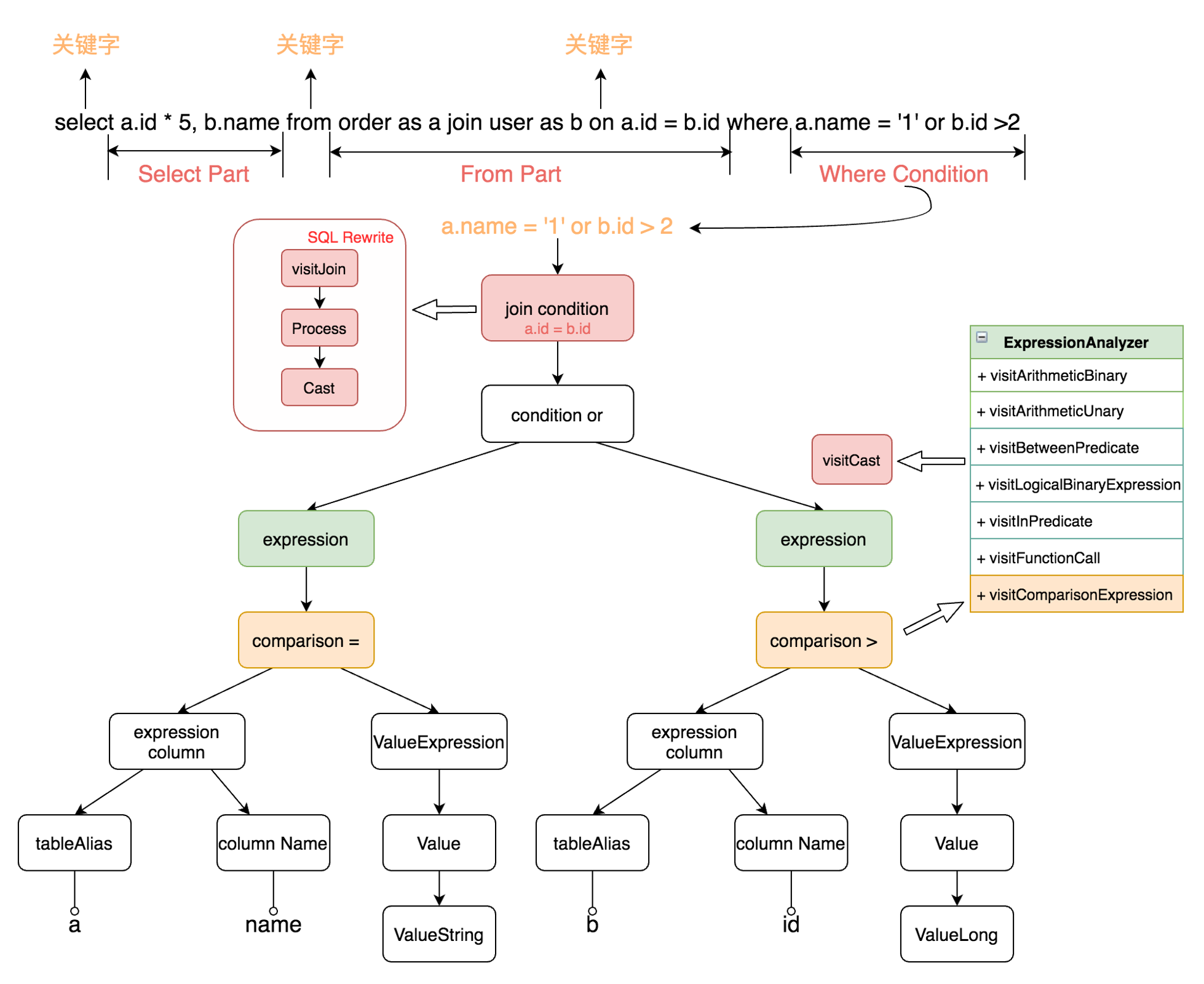
主要工作:
- 隐式类型转换
- 语义兼容
- 语法兼容
- 支持Hive视图
- Parquet HDFS文件读取支持
- 大量UDF支持
- 其他
Hive SQL兼容,我们迭代了三个大版本,目前线上SQL通过率97% ~ 99%。而业务从Spark/Hive迁移到Presto后,查询性能平均提升30% ~ 50%,甚至一些场景提升10倍,Ad-Hoc场景共节省80%机器资源。下图是线上Presto集群的SQL查询通过率及失败原因占比,’null’ 表示查询成功的SQL,其他表示错误原因:
2、物理资源隔离
上文说到,对性能要求高的业务与大查询业务方混合跑,查询性能容易受到影响,只有单独搭建集群。而单独搭建集群导致Presto集群太多,维护成本太高。因为目前我们Presto Coordinator还没有遇到瓶颈,大查询主要影响Worker性能,比如一条大SQL导致Worker CPU打满,导致其他业务方SQL查询变慢。所以我们修改调度模块,让Presto支持可以动态打Label,动态调度指定的 Label 机器。如下图所示:

根据不同的业务划分不同的label,通过配置文件配置业务方指定的label和其对应的机器列表,Coordinator会加载配置,在内存里维护集群label信息,同时如果配置文件里label信息变动,Coordinator会定时更新label信息,这样调度时根据SQL指定的label信息来获取对应的Worker机器,如指定label A时,那调度机器里只选择Worker A 和 Worker B 即可。这样就可以做到让机器物理隔离了,对性能要求高的业务查询既有保障了。
3、Druid Connector
使用 Presto + HDFS 有一些痛点:
- latency高,QPS较低
- 不能查实时数据,如果有实时数据需求,需要再构建一条实时数据链路,增加了系统的复杂性
- 要想获得极限性能,必须与HDFS DataNode 混部,且DataNode使用高级硬件,有自建HDFS的需求,增加了运维的负担
所以我们在0.215版本实现了Presto on Druid Connector,此插件有如下优点:
- 结合 Druid 的预聚合、计算能力(过滤聚合)、Cache能力,提升Presto性能(RT与QPS)
- 让 Presto 具备查询 Druid 实时数据能力
- 为Druid提供全面的SQL能力支持,扩展Druid数据的应用场景
- 通过Druid Broker获取Druid元数据信息
- 从Druid Historical直接获取数据
- 实现了Limit下推、Filter下推、Project下推及Agg下推
在PrestoSQL 340版本,社区也实现了Presto on Druid Connector,但是此Connector是通过JDBC实现的,缺点比较明显:
- 无法划分多个Split,查询性能差
- 请求查询Broker,之后再查询Historical,多一次网络通信
- 对于一些场景,如大量Scan场景,会导致Broker OOM
- Project及Agg下推支持不完善
详细架构图见:
使用了Presto on Druid后,一些场景,性能提升4~5倍。
4、易用性建设
为了支持公司的几个核心数据平台,包括:数梦、提取工具、数易及特征加速及各种散户,我们对Presto做了很多二次开发,包括权限管理、语法支持等,保证了业务的快速接入。主要工作:
- 租户与权限
- 与内部Hadoop打通,使用HDFS SIMPLE协议做认证
- 使用Ranger做鉴权,解析SQL使Presto拥有将列信息传递给下游的能力,提供用户名+数据库名/表名/列名,四元组的鉴权能力,同时提供多表同时鉴权的能力
- 用户指定用户名做鉴权和认证,大账号用于读写HDFS数据
- 支持视图、表别名鉴权
- 语法拓展
- 支持add partition
- 支持数字开头的表
- 支持数字开头的字段
- 特性增强
- insert数据时,将插入数据的总行数写入HMS,为业务方提供毫秒级的元数据感知能力
- 支持查询进度滚动更新,提升了用户体验
- 支持查询可以指定优先级,为用户不同等级的业务提供了优先级控制的能力
- 修改通信协议,支持业务方可以传达自定义信息,满足了用户的日志审计需要等
- 支持DeprecatedLzoTextInputFormat格式
- 支持读HDFS Parquet文件路径
5、稳定性建设
Presto在使用过程中会遇到很多稳定性问题,比如Coordinator OOM,Worker Full GC等,为了解决和方便定位这些问题,首先我们做了监控体系建设,主要包括:
- 通过Presto Plugin实现日志审计功能
- 通过JMX获取引擎指标将监控信息写入Ganglia
- 将日志审计采集到HDFS和ES;统一接入运维监控体系,将所有指标发到 Kafka;
- Presto UI改进:可以查看Worker信息,可以查看Worker死活信息
通过以上功能,在每次出现稳定性问题时,方便我们及时定位问题,包括指标查看及SQL回放等,如下图所示,可以查看某集群的成功及失败SQL数,我们可以通过定义查询失败率来触发报警:

在Presto交流社区,Presto的稳定性问题困扰了很多Presto使用者,包括Coordinator和Worker挂掉,集群运行一段时间后查询性能变慢等。我们在解决这些问题时积累了很多经验,这里说下解决思路和方法。
根据职责划分,Presto分为Coordinator和Worker模块,Coordinator主要负责SQL解析、生成查询计划、Split调度及查询状态管理等,所以当Coordinator遇到OOM或者Coredump时,获取元信息及生成Splits是重点怀疑的地方。而内存问题,推荐使用MAT分析具体原因。如下图是通过MAT分析,得出开启了FileSystem Cache,内存泄漏导致 OOM。

这里我们总结了Coordinator常见的问题和解决方法:
- 使用HDFS FileSystem Cache导致内存泄漏,解决方法禁止FileSystem Cache,后续Presto自己维护了FileSystem Cache
- Jetty导致堆外内存泄漏,原因是Gzip导致了堆外内存泄漏,升级Jetty版本解决
- Splits太多,无可用端口,TIME_WAIT太高,修改TCP参数解决
- JVM Coredump,显示”unable to create new native thread”,通过修改pid_max及max_map_count解决
- Presto内核Bug,查询失败的SQL太多,导致Coordinator内存泄漏,社区已修复
而Presto Worker主要用于计算,性能瓶颈点主要是内存和CPU。内存方面通过三种方法来保障和查找问题:
- 通过Resource Group控制业务并发,防止严重超卖
- 通过JVM调优,解决一些常见内存问题,如Young GC Exhausted
- 善用MAT工具,发现内存瓶颈
而Presto Worker常会遇到查询变慢问题,两方面原因,一是确定是否开启了Swap内存,当Free内存不足时,使用Swap会严重影响查询性能。第二是CPU问题,解决此类问题,要善用Perf工具,多做Perf来分析CPU为什么不在干活,看CPU主要在做什么,是GC问题还是JVM Bug。如下图所示,为线上Presto集群触发了JVM Bug,导致运行一段时间后查询变慢,重启后恢复,Perf后找到原因,分析JVM代码,可通过JVM调优或升级JVM版本解决:

这里我们也总结了Worker常见的问题和解决方法:
- Sys load过高,导致业务查询性能影响很大,研究jvm原理,通过参数(-XX:PerMethodRecompilationCutoff=10000 及 -XX:PerBytecodeRecompilationCutoff=10000)解决,也可升级最新JVM解决
- Worker查询hang住问题,原因HDFS客户端存在bug,当Presto与HDFS混部署,数据和客户端在同一台机器上时,短路读时一直wait锁,导致查询Hang住超时,Hadoop社区已解决
- 超卖导致Worker Young GC Exhausted,优化GC参数,如设置-XX:G1ReservePercent=25 及 -XX:InitiatingHeapOccupancyPercent=15
- ORC太大,导致Presto读取ORC Stripe Statistics出现OOM,解决方法是限制ProtoBuf报文大小,同时协助业务方合理数据治理
- 修改Presto内存管理逻辑,优化Kill策略,保障当内存不够时,Presto Worker不会OOM,只需要将大查询Kill掉,后续熔断机制会改为基于JVM,类似ES的熔断器,比如95% JVM 内存时,Kill掉最大SQL
6、引擎优化及调研
作为一个Ad-Hoc引擎,Presto查询性能越快,用户体验越好,为了提高Presto的查询性能,在Presto on Hive场景,我们做了很多引擎优化工作,主要工作:
- 某业务集群进行了JVM调优,将Ref Proc由单线程改为并行执行,普通查询由30S~1分钟降低为3-4S,性能提升10倍+
- ORC数据优化,将指定string字段添加了布隆过滤器,查询性能提升20-30%,针对一些业务做了调优
- 数据治理和小文件合并,某业务方查询性能由20S降低为10S,性能提升一倍,且查询性能稳定
- ORC格式性能优化,查询耗时减少5%
- 分区裁剪优化,解决指定分区但获取所有分区元信息问题,减少了HMS的压力
- 下推优化,实现了Limit、Filter、Project、Agg下推到存储层
18年我们为了提高Presto查询性能,也调研了一些技术方案,包括Presto on Alluxio和Presto on Carbondata,但是这2种方案最后都被舍弃了,原因是:
- Presto on Alluxio查询性能提升35%,但是内存占用和性能提升不成正比,所以我们放弃了Presto on Alluxio,后续可能会对一些性能要求敏感的业务使用
- Presto on Carbondata是在18年8月份测试的,当时的版本,Carbondata稳定性较差,性能没有明显优势,一些场景ORC更快,所以我们没有再继续跟踪调研Presto on Carbondata。因为滴滴有专门维护Druid的团队,所以我们对接了Presto on Druid,一些场景性能提升4~5倍,后续我们会更多关注Presto on Clickhouse及Presto on Elasticsearch
总结
通过以上工作,滴滴Presto逐渐接入公司各大数据平台,并成为了公司首选Ad-Hoc查询引擎及Hive SQL加速引擎,下图可以看到某产品接入后的性能提升:
上图可以看到大约2018年10月该平台开始接入Presto,查询耗时TP50性能提升了10+倍,由400S降低到31S。且在任务数逐渐增长的情况下,查询耗时保证稳定不变。
而高性能集群,我们做了很多稳定性和性能优化工作,保证了平均查询时间小于2S。如下图所示:

展望
Presto主要应用场景是Ad-Hoc查询,所以其高峰期主要在白天,如下图所示,是网约车业务下午12-16点的查询,可以看到平均CPU使用率在40%以上。

但是如果看最近一个月的CPU使用率会发现,平均CPU使用率比较低,且波峰在白天10~18点,晚上基本上没有查询,CPU使用率不到5%。如下图所示:

所以,解决晚上资源浪费问题是我们今后需要解决的难题。
同时,为了不与开源社区脱节,我们打算升级PrestoDB 0.215到PrestoSQL 340版本,届时会把我们的Presto on Druid代码开源出来,回馈社区。