刚接触ES,研究了下ES内存管理,参考了一些文章,整理了一篇文章,方便自己记忆。
命令 GET _cat/nodes?help 列出所有node, 并展示node所在机器的运行状态信息,help可显示帮助信息
1 | GET _cat/nodes?h=name,hp,hm,rp,rm,qcm,rcm,fm,sm&v |
解析下上面参数的意义

信息如下:
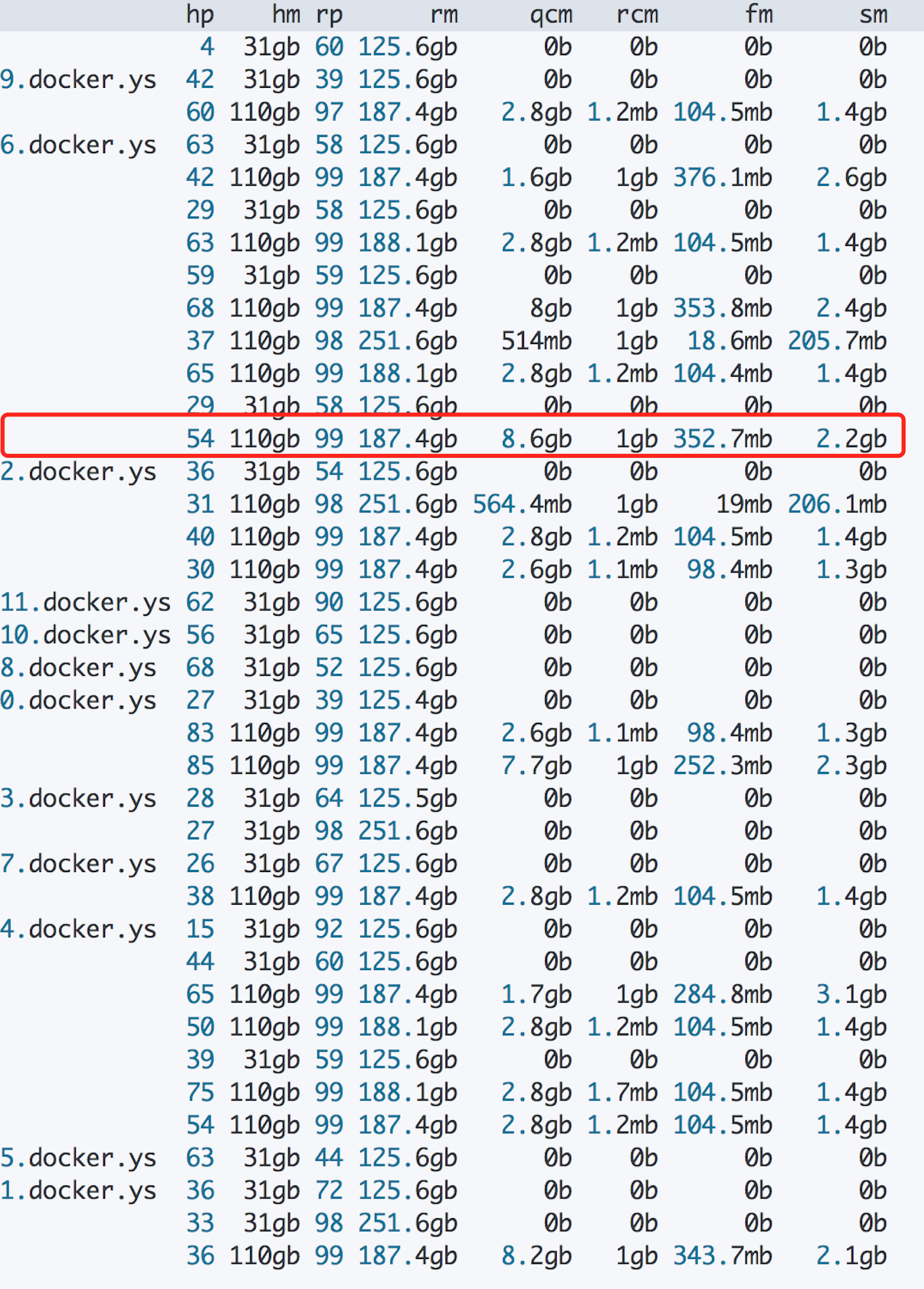
以红框里的node为例, 内存占用 = (8.6 gb)qcm + (1gb) rcm + (0.35gb) fm + (2.2 gb)sm,大约12 gb。
内存占用有2种,一种是ES可以管理的 on-heap 内存,另一种是由Lucene管理的 off-heap 内存。
On Heap
根据缓存占用的作用,可以分为以下五种缓存:节点查询缓存、分片请求缓存、Fielddata Cache、Segments FST Cache、Indexing Buffer(无参数可看占用的大小)。
节点查询缓存
Node Query Cache (node 级别的 filter 过滤器结果缓存), 每个节点有一个,被所有 shard 共享,filter query 结果要么是 yes 要么是no,不涉及 scores 的计算。使用LRU淘汰策略,内存无法被GC。
集群中每个节点都要配置,indices.queries.cache.size: 10%,默认为 10%。index.queries.cache.enabled 用来控制具体索引是否启用缓存,默认是开启的。属于 index 级别配置,只用在索引创建时候或者关闭的索引上设置。
分片请求缓存
Shard Request Cache (shard 级别的 query result 缓存)每个 shard 一个,默认情况下该缓存只缓存 request 的结果 size 为0的查询。所以该缓存不会缓存hits,但却会缓存 hits.total, aggregations 和 suggestions,默认值:indices.requests.cache.size: 1%
Fielddata Cache
Field Data Cache (OLAP场景,用于排序、聚合使用的字段的缓存)。对于Text类型的字段,如果要对其进行聚合和排序,则需要打开字段的Fileddata属性。Fielddata 是延迟加载。如果你从来没有聚合一个分析字符串,就不会加载 fielddata 到内存中。如果没有足够的内存保存 fielddata 时,Elastisearch会不断地从磁盘加载数据到内存,并剔除掉旧的内存数据。剔除操作会造成严重的磁盘I/O,并且引发大量的GC,会严重影响Elastisearch的性能。
通过参数 indices.fielddata.cache.size: 30% 配置,默认情况下Fielddata会不断占用内存,无上限,直到它触发了 fielddata circuit breaker。
fielddata circuit breaker会根据查询条件评估这次查询会使用多少内存,从而计算加载这部分内存之后,Field Data Cache所占用的内存是否会超过 indices.breaker.fielddata.limit。如果超过这个值,就会触发fielddata circuit breaker,abort这次查询并且抛出异常,防止OOM。
indices.breaker.fielddata.limit: 60% (默认heap的60%) ,如果设置了indices.fielddata.cache.size,当达到size时,cache会剔除旧的fielddata。注意,indices.breaker.fielddata.limit 必须大于 indices.fielddata.cache.size,否则只会触发fielddata circuit breaker,而不会剔除旧的fielddata。
Segments FST Cache
Segments Cache(segments FST数据的缓存),为了加速查询,FST 永驻堆内内存,无法被 GC 回收。该部分内存无法设置大小,减少data node上的segment memory占用,有三种方法:
- 删除不用的索引。
- 关闭索引(文件仍然存在于磁盘,只是释放掉内存),需要的时候可重新打开。
- 定期对不再更新的索引做force merge
解释下FST
ES 底层存储采用 Lucene(搜索引擎),写入时会根据原始数据的内容,分词,然后生成倒排索引。查询时先通过查询倒排索引找到数据地址(DocID),再读取原始数据(行存数据、列存数据)。但由于 Lucene 会为原始数据中的每个词都生成倒排索引,数据量较大。所以倒排索引对应的倒排表被存放在磁盘上。这样如果每次查询都直接读取磁盘上的倒排表,再查询目标关键词,会有很多次磁盘 IO,严重影响查询性能。为了解磁盘 IO 问题,Lucene 引入排索引的二级索引 FST [Finite State Transducer] 。原理上可以理解为前缀树,加速查询。
Indexing Buffer
Indexing Buffer 索引写入缓冲区,用于存储新写入的文档,当其被填满时,缓冲区中的文档被写入磁盘中的 segments 中。节点上所有 shard 共享。这部分空间是可以被GC的,缓冲区默认大小 10%。
Off-heap
上面的提到的内存都是JVM管理的,ES能控制,即On-heap内存,ES还有Off-heap内存,由Lucene管理,负责缓存倒排索引(Segment Memory)。Lucene 中的倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到内存中,从而提高 Lucene 性能。
总结

缓存的清除
清除全部的缓存:
1 | POST /_cache/clear |
清除特定索引的缓存:
1 | POST /my_index/_cache/clear |
通过设置fielddata, query, request参数为true来清除特定类型的缓存清除特定类型缓存:
1 | POST /my-index/_cache/clear?fielddata=true |
通过上面分析,ES内存管理主要是谨慎对待unbounded的内存。unbounded内存是不可控的,会占用大量的 heap (Field Data Cache)或者 off heap(segments会长期占用内存,其初衷就是利用OS的cache提升性能。只有在Merge之后,才会释放掉标记为Delete的segments,释放部分内存),从而会导致Elasticsearch OOM。
查看Cache对应的类
一个小技巧,测试环境对ES jmap下,之后MAT分析,选择dominator_tree,之后group by class,然后模糊匹配 Cache 关键字,之后可以看到一些关键类,比如IndicesRequestCache和IndicesFieldDataCache,而 FST Cache我还没有找到对应的类,还需要继续熟悉下代码。
