前言
好几年前的文章了,之前排查问题,随手写的,但是发现其他团队人遇到类似问题没有思路,所以还是发出来,给大家一起解决问题的思路。
问题描述
ES集群磁盘报警,发现/home/coresave/ core文件导致根目录磁盘被打满,删除core文件恢复,已知这个集群新上线了jdk 17 zgc,排查下jvm为啥core。而jvm core一般有以下几个原因:资源超了(内存、线程数,vma数等),jvm bug(比如指令集)
排查过程
先去elasticsearch根目录查看core日志,即hs_err_pid_xxx.log,内容如下:
看core原因是因为资源不足(不一定是内存)导致的问题,jdk 17 zgc core后,fatal error 原因与g1 有明显不同,突然不知道怎么去排查了,研究下,思路如下。资源不足原因我们可以在hs_err.log里查看具体的原因,步骤如下:
1、先排查meminfo,看下机器内存情况
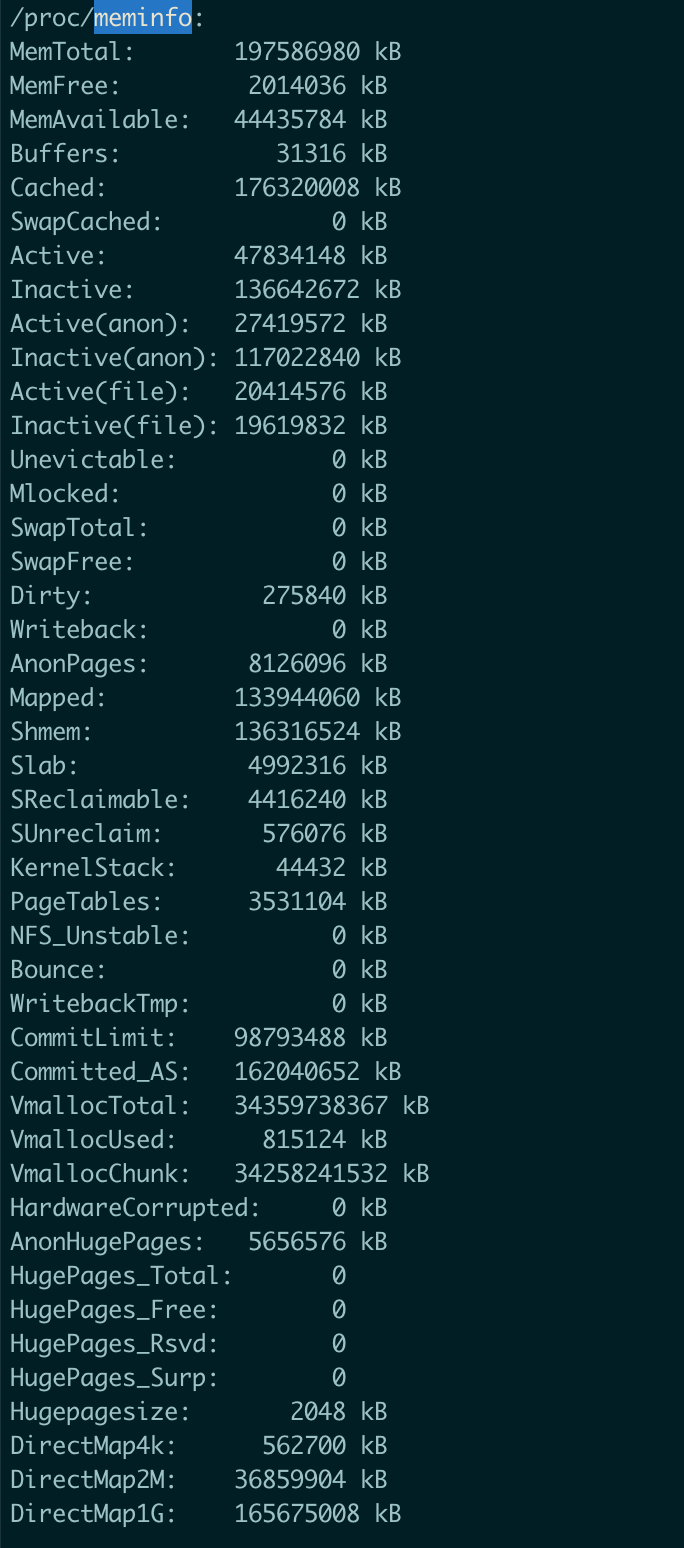
通过上面的MemAvailable可以判断,机器内存是足够的,core与机器内存没关系。
2、判断是否是线程数超了
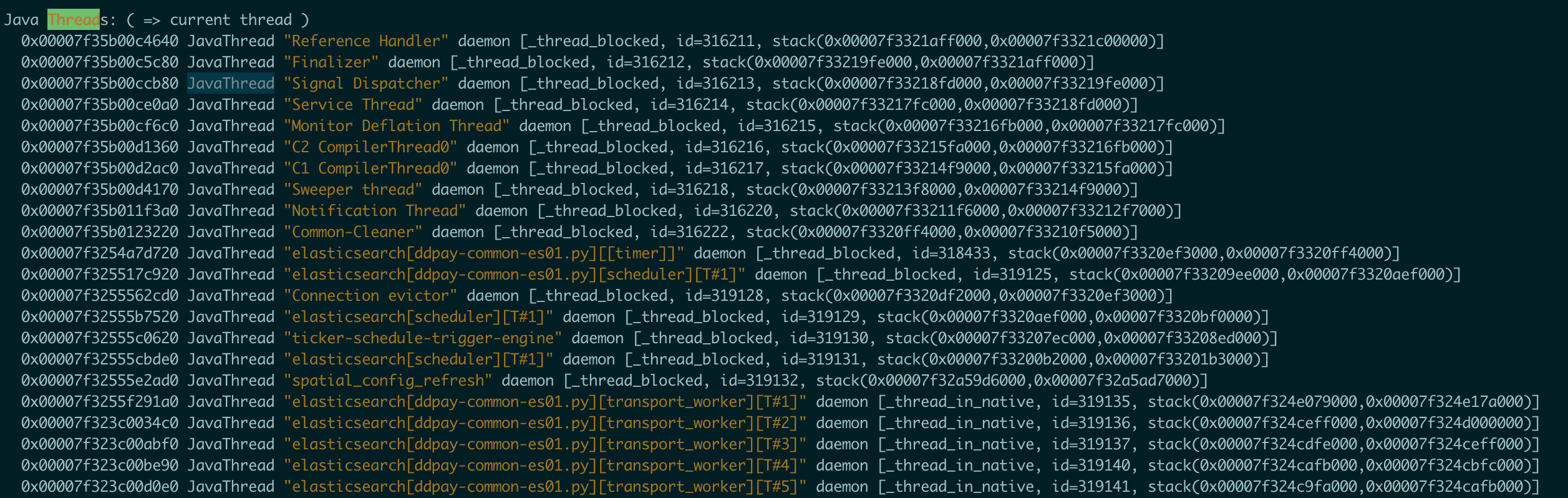
1 | user@hostname:/data0/elasticsearch$ grep "JavaThread" hs_err_pid314151.log | wc -l |
查看线程数,可以看到线程数只有599个,而jvm线程最大值是 1/2 max_map_count (vma最大值)
1 | user@hostname:/data0/elasticsearch$ cat /proc/sys/vm/max_map_count |
3、判断是否是虚拟内存块(vma)超了
搜索Dynamic libraries,查看这个区域的个数,每一行是一个vma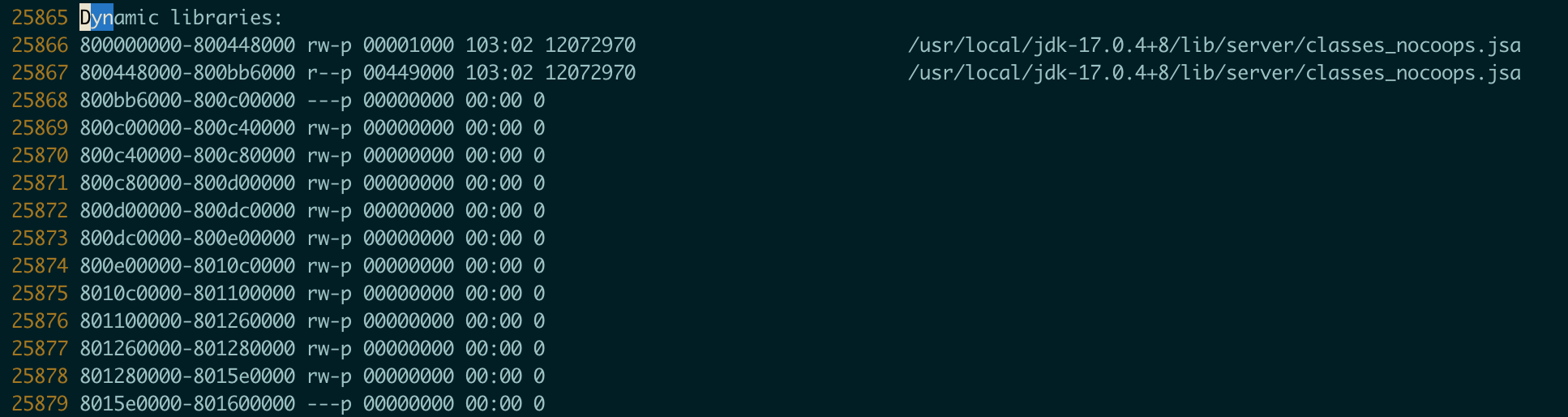
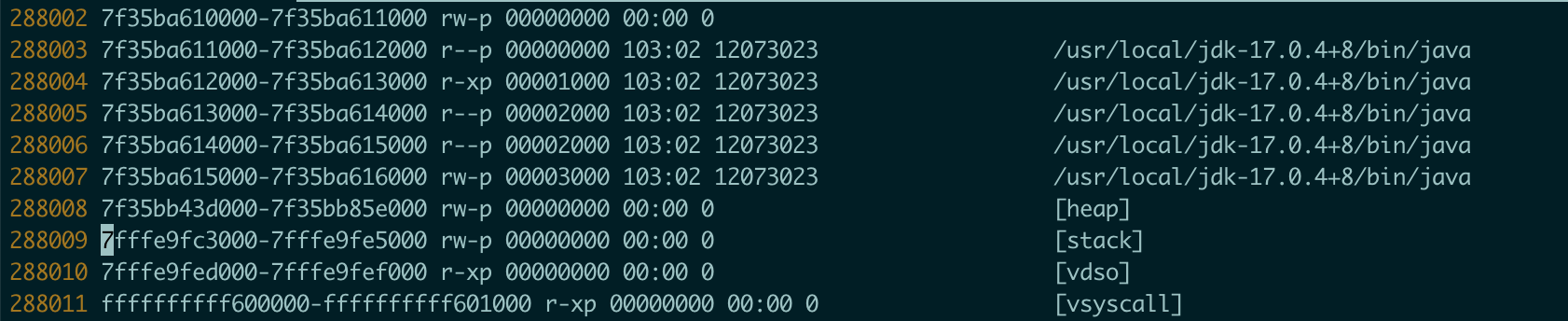
可以看到末值减去初值 = 288011 - 25866 = 212645 超过了vma的最大值 262144。
所以jvm core掉的原因是因为vma不够了。
问题追踪
那为什么vma 不够了,查看了下vma: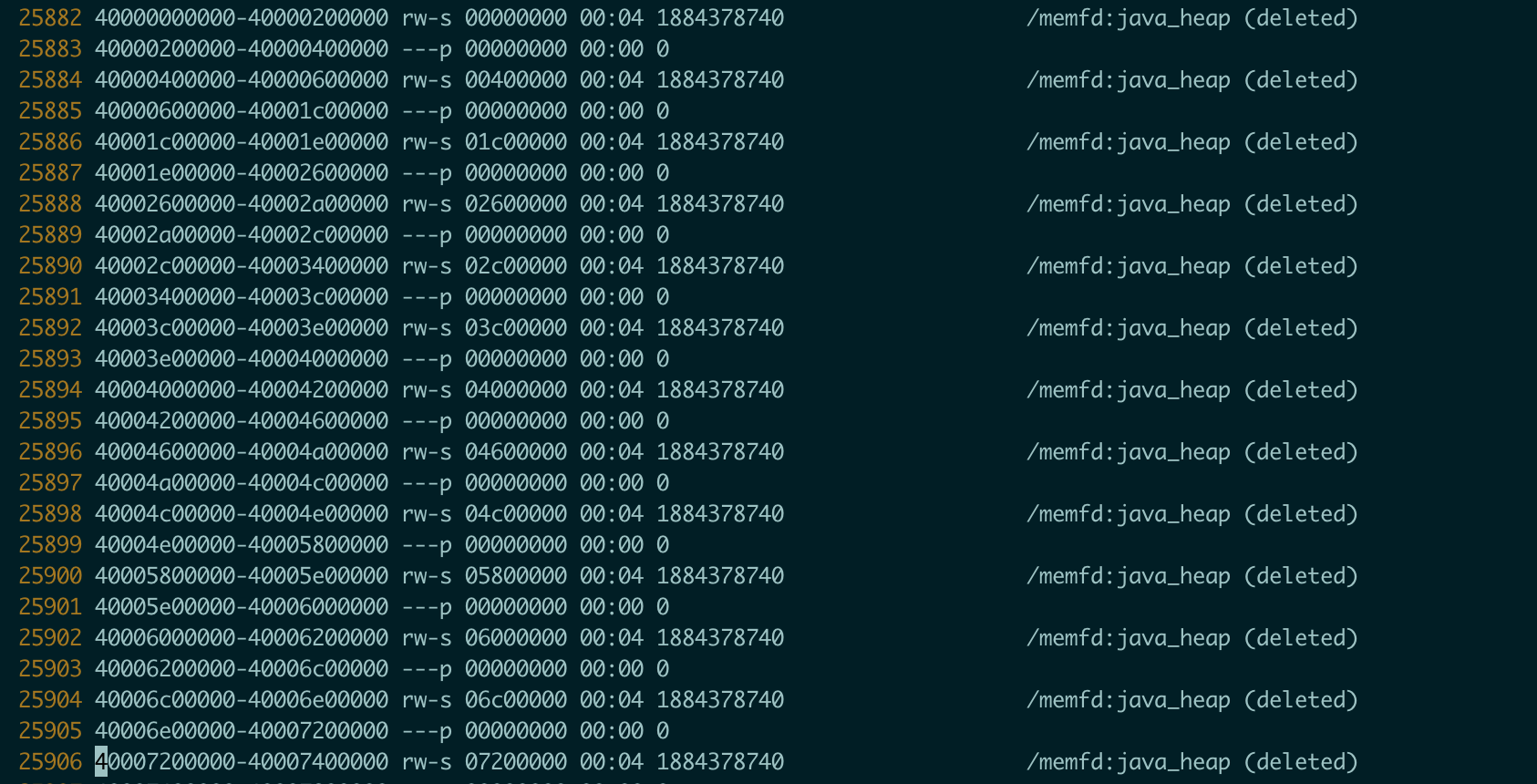
发现多了很多(12W个)/memfd:java_heap (deleted) vma,搜索发现下zgc引入的内存管理的东西,在g1里是没有这个东西的,导致直接多了12W个vma。另一方面,集群3台机器,但是一台机器故障,数据迁移导致集群的索引文件数太多,如下: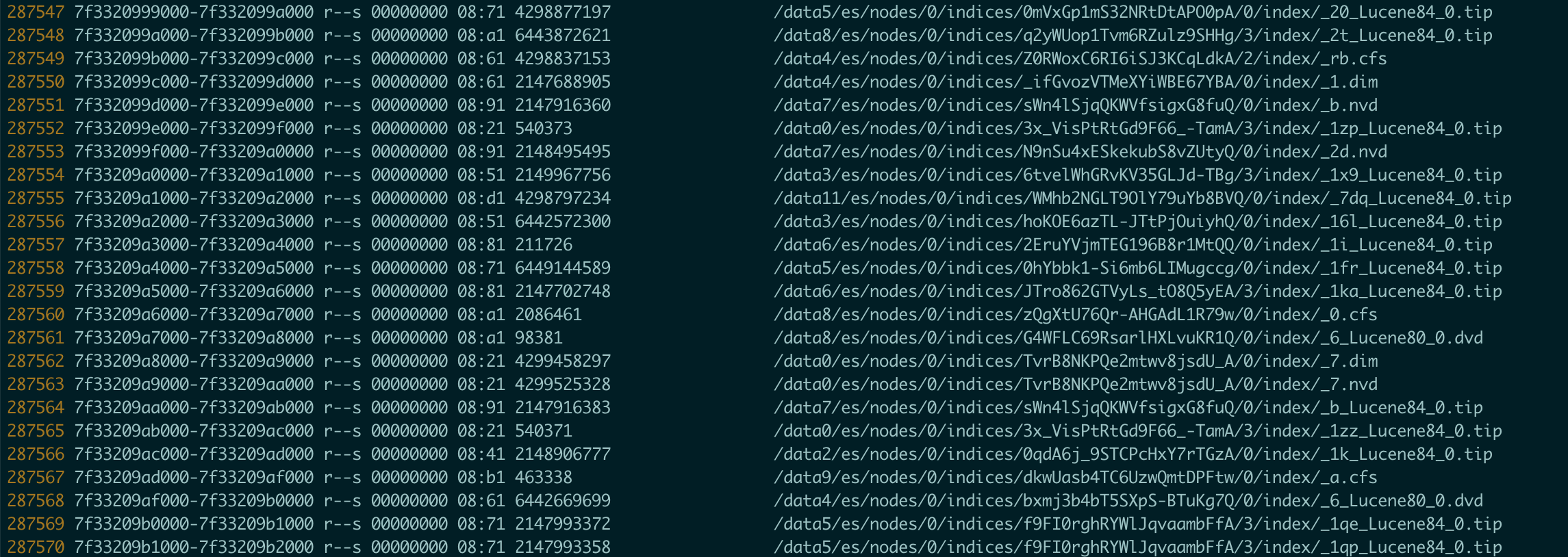
解决方法
1、修改 /proc/sys/vm/max_map_count 值,值扩大一倍。