滴滴 Elasticsearch 简介
简介
Elasticsearch 是一个基于 Lucene 构建的开源、分布式、RESTful 接口的全文搜索引擎,其每个字段均可被索引,且能够横向扩展至数以百计的服务器存储以及处理 TB 级的数据,其可以在极短的时间内存储、搜索和分析大量的数据。
滴滴 ES 发展至今,承接了公司绝大部分端上文本检索、少部分日志场景和向量检索场景,包括地图 POI 检索、订单检索、客服、内搜及把脉日志 ELK 场景等。滴滴 ES 在2020年由2.X升级到7.6.0,近几年围绕保稳定、控成本、提效能和优生态这几个方向持续探索和改进,本文会围绕这几个方向展开介绍。
架构

滴滴 ES 整体产品架构如上图所示,目前ES服务基于物理机部署,Gateway 和管控基于容器部署,我们也调研过 ES on K8S,因为我们 ES 的业务场景多是在线端上文本检索,考虑到稳定性,所以最后还是决定使用物理机部署模式。
管控层主要负责实现以下功能:智能 segment Merge(防止 segment 膨胀导致 datanode Full GC),索引生命周期管理,索引预创建(避免每天凌晨索引集中创建,导致 Master/Clientnode OOM),租户管控等。
网关层(Gateway)除了负责读写转发外,还具备查询优化能力(例如,将 BKD 查询改写为数值类型的等值查询或范围查询)、三级限流(包括 AppID、索引模板级别和查询 DSL 级别)、租户鉴权功能以及 SQL 能力(基于 NLPChina 开源的 ES SQL 能力进行魔改并封装到 Gateway)等。我们的检索服务仅对外暴露 Gateway 接口。
用户控制台
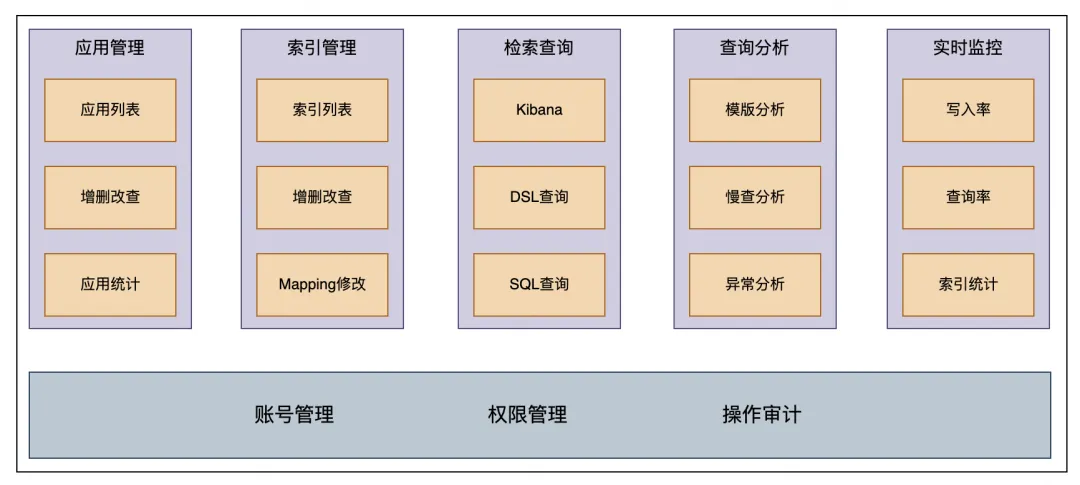
用户控制台是我们提供给业务方产品接入的平台,主要功能:
- 应用管理:允许业务方通过申请 AppID 来获取读写索引的权限。
- 索引管理:支持新建索引、申请索引读写权限、索引 mapping 创建和更改、以及索引的清理和下线操作。
检索查询提供多种查询方式,包括 Kibana、DSL 和 SQL,以满足不同的查询需求。
同时业务方可以在查询分析模块看到对应的异常分析和慢查分析等,方便查询优化。监控方面业务方可以查看索引元信息(如文档数及大小等)以及读写速率等,以监控系统运行状态。
运维管控平台
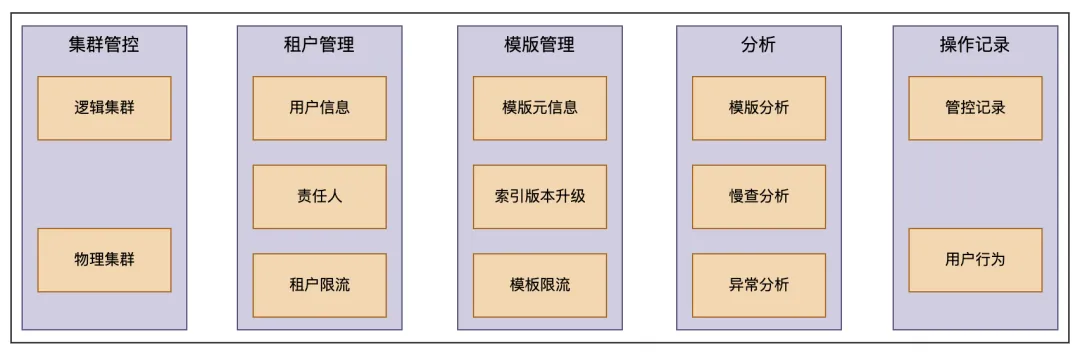
运维管控平台主要是满足 RD 和 SRE 日常运维需求,主要功能包括以下几个方面:
- 集群管控:展示集群信息,对用户暴露的是逻辑集群,一个逻辑集群可包含多个物理集群,如用户看到的集群信息是一个 important 公共集群,但是真实的物理集群包含几十个小的公共 important 集群
- 租户管理(租户元信息和租户级别的限流)
- 模版管理:索引模板元数据管理,非更新索引可以通过升版本调整 shard 数,也可以在此处对索引模板限流
- 异常分析:模版分析、慢查分析及异常分析
- 操作记录:用户行为及管控定时任务记录
Elasticsearch 在滴滴的应用
业务场景
- 在线全文检索服务,如地图 POI 起终点检索,详细优化过程见:https://mp.weixin.qq.com/s/cc1lCi5YcZq048EjxwlBVw
- MySQL 实时数据快照,在线业务如订单查询
- 一站式日志检索服务,通过 Kibana 查询,如 trace 日志
- 时序数据分析,如安全数据监控
- 简单 OLAP 场景,如内部数据看板
- 向量检索,如客服 RAG
部署模式
- 物理机+小集群部署方式,最大集群机器规模100台物理机左右
接入方式
- 通过用户控制台创建索引,业务方根据业务需求选择对应集群
- 通过网关查询,根据集群等级提供 gateway vip 地址,该网关是一个 HTTP 类型的服务,我们做了兼容,业务方可以通过官方提供的SDK读写Gateway,Gateway 会根据索引找到对应的ES集群
数据同步方式
一共两种数据同步方式,一种是走同步中心(公司数据平台提供统一的同步服务),一种是通过 Gateway 实时写入,同步中心支持实时类和离线类的数据同步方式。
实时类:
- 日志 -> ES
- MQ(Kafka、Pulsar)-> ES
- MySQL -> ES
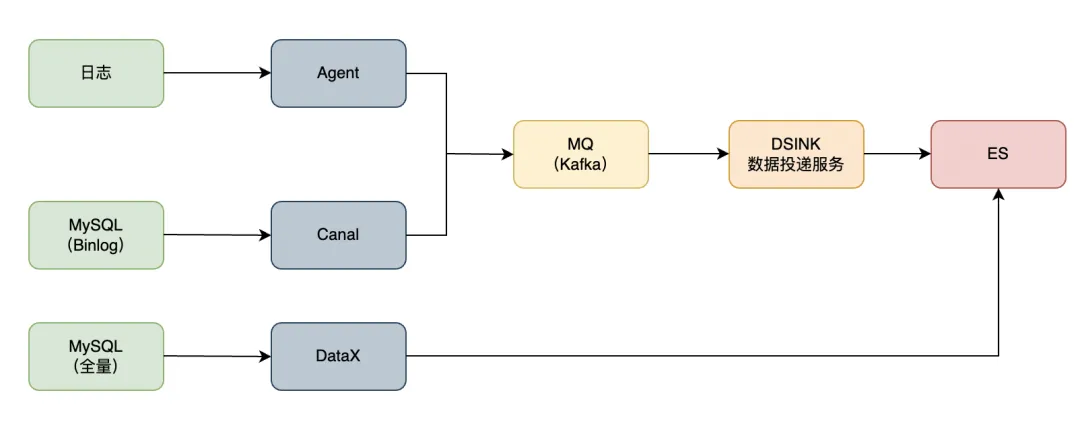 如上图所示,实时类同步方式有2种,一种是日志和 MySQL Binlog 通过采集工具采集到 MQ,之后通过统一封装的 DSINK 工具,通过 Flink 写入到 ES;另一种是 MySQL 全量数据,其基于开源的 DataX 进行全量数据同步。
如上图所示,实时类同步方式有2种,一种是日志和 MySQL Binlog 通过采集工具采集到 MQ,之后通过统一封装的 DSINK 工具,通过 Flink 写入到 ES;另一种是 MySQL 全量数据,其基于开源的 DataX 进行全量数据同步。
离线类:
- Hive -> ES
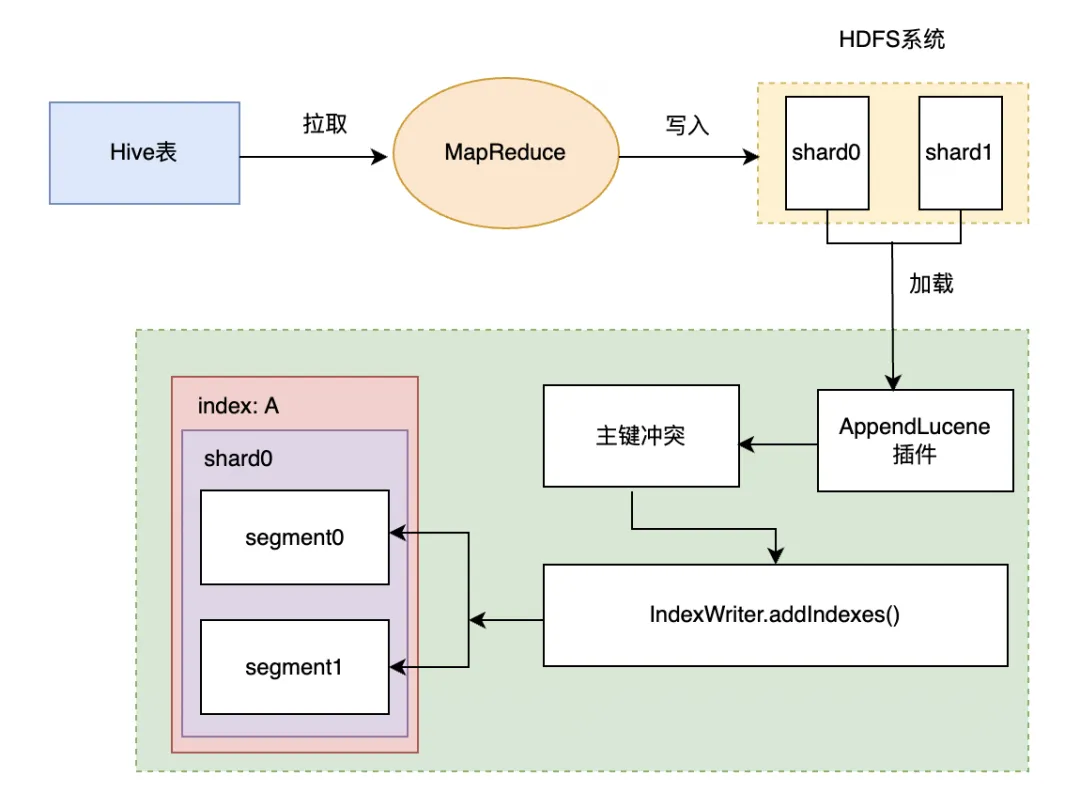 Hive->ES 整体思路是通过 Batch Load,加快数据导入。通过 MR 生成 Lucene 文件,之后通过封装的 ES AppendLucene 插件把 Lucene 文件写入到 ES 中。Hive->ES 整体流程,如上图所示:
Hive->ES 整体思路是通过 Batch Load,加快数据导入。通过 MR 生成 Lucene 文件,之后通过封装的 ES AppendLucene 插件把 Lucene 文件写入到 ES 中。Hive->ES 整体流程,如上图所示: - 使用 MR 生成 Lucene 文件
- Lucene 保存在 HDFS 里
- 将文件拉取到 DataNode 里
- 导入到 ES 中
引擎迭代
精细化分级保障
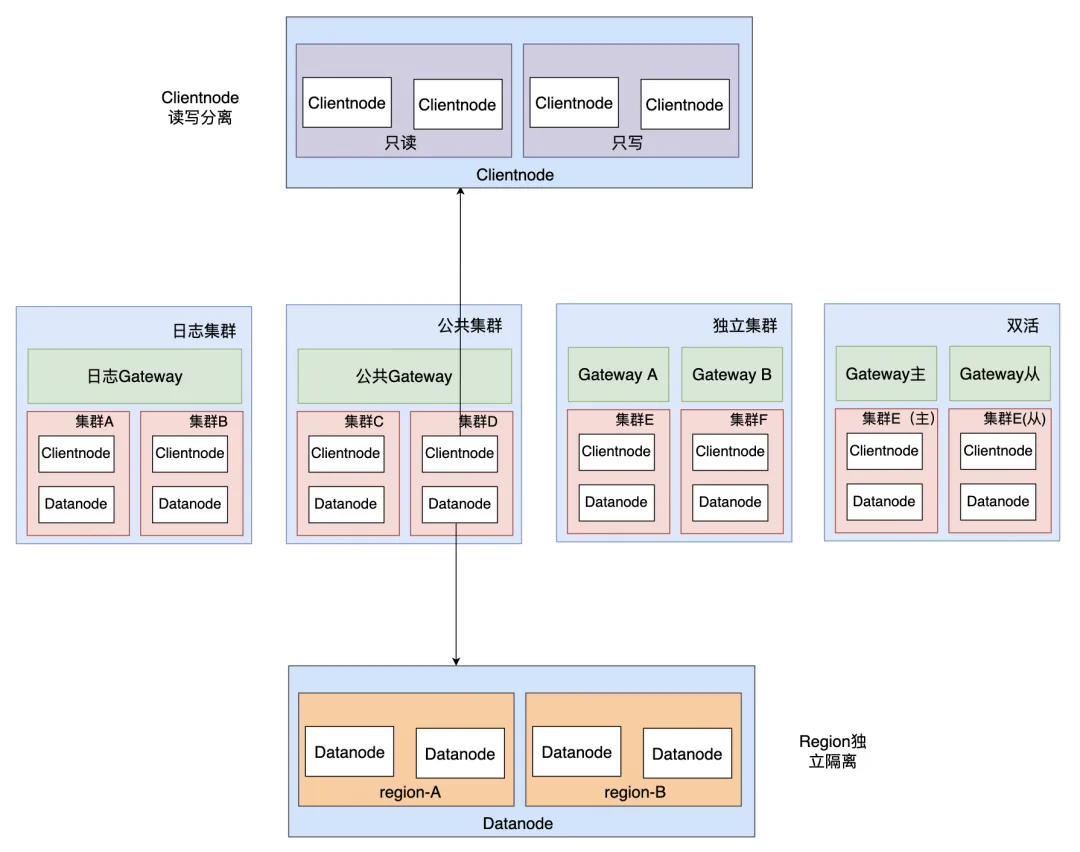 精细化分级保障主要解决的问题是当集群出现故障时,影响面降低到最低,主要包括以下策略:
精细化分级保障主要解决的问题是当集群出现故障时,影响面降低到最低,主要包括以下策略:
- 集群级别隔离:4种保障级别(日志集群、公共集群、独立集群和双活集群),业务接入时,会在用户控制台选择其想要的集群。如果选错集群我们会通过 DCDR(下文介绍)帮助业务在不影响业务且不感知的前提下迁移到其他集群。
- Clientnode 隔离:Clientnode 读写分离,当 Clientnode 异常时,能快速定位故障原因也能减少影响面。如集群写入慢且写入量过大,Clientnode 可能导致 OOM,此时只会影响写入不会影响查询,可以降低业务的影响面。
- Datanode Region 隔离:当集群出现异常索引(如异常索引导致整个 datanode 写入过慢)时,可以通过打 label 的方式,让异常索引快速迁移到指定机器,避免影响集群上其他业务。
多活建设
滴滴跨数据中心复制能力 - Didi Cross Datacenter Replication,由滴滴自研,简称DCDR,它能够将数据从一个 Elasticsearch 集群原生复制到另一个 Elasticsearch 集群。原理如下图所示,DCDR 工作在索引模板或索引层面,采用主从索引设计模型,由 Leader 索引主动将数据 push 到 Follower 索引,从而保证了主从索引数据的强一致性。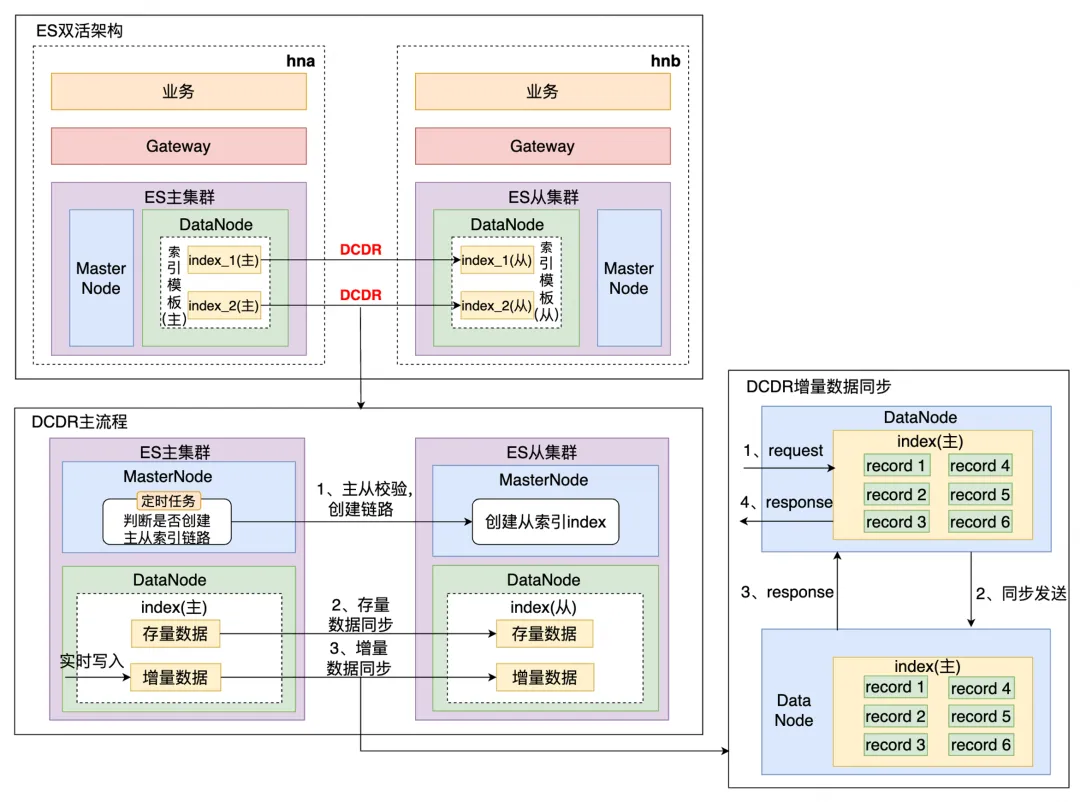
我们调研了官方自带的的 ES CCR,发现其收费且基于 pull-based 模型,时效性较差,所以我们的 DCDR 方案是:
- Push-based 模型,实时写入基于 Request
- 新增 CheckPoint 避免全量数据拷贝
- 新增 Sequence Number 保障更新操作主从一致性
- 引入写入队列,避免大量数据复制导致 OOM
DCDR解决了数据跨集群或者跨机房的数据实时同步问题,且我们基于管控实现了双活能力。
ES DCDR 的详细解析见:《探索ES高可用:滴滴自研跨数据中心复制技术详解》
性能专项:JDK17 + ZGC
JDK11-G1 Yong GC 平均暂停时间长,不满足业务 P99 要求,如 POI 超时,时是180ms,P99 要求60ms内,支付业务 P99 500ms,订单业务 P99 400ms;写入数据量大的场景,GC 频繁,加剧集群写入 reject 问题,写入延时大,不满足业务需求。
基于上述背景,我们对 JDK17-ZGC 进行调研,经过测试 ZGC 可以将 GC 暂停时间控制在10ms内,能够很好地解决 GC 导致的查询耗时问题。同时针对日志这种高吞吐场景,测试了JDK17-G1,发现 GC 性能相较于 JDK11-G1 提升了15%,并且 JDK17 在向量化支持、字符串处理等方面做了许多优化,能在一定程度上缓解日志集群的写入压力。所以我们决定将 ES JDK 版本从11升级到17,并将部分业务 GC 算法从 G1 升级到 ZGC,主要工作如下:
- Groovy 语法升级、 Plugin 插件重构
- 解决语法格式导致代码编译失败问题
- 解决 ES 源码触发 JVM 编译 BUG
- 依赖 Jar 包升级、类替换、类重构、注解优化
- 搭建 ZGC 监控指标体系
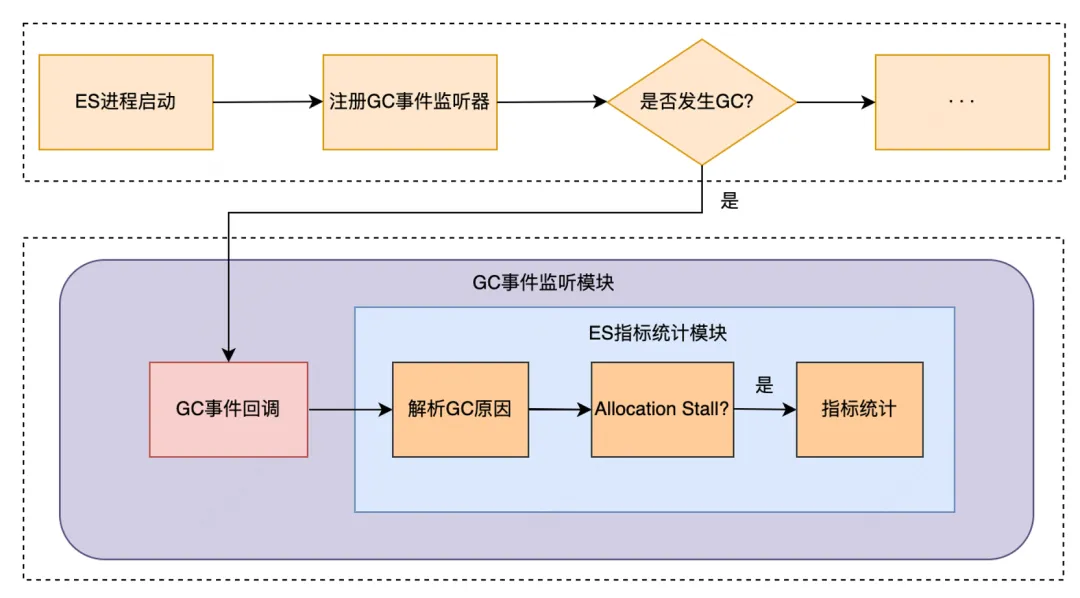 支付集群上线ZGC后,P99从800ms降低到30ms,下降96%平均查询耗时从25ms降低到6ms,下降75%。日志集群升级JDK17后,写入性能提升15~20%,解决写入队列堆积和 reject 问题。
支付集群上线ZGC后,P99从800ms降低到30ms,下降96%平均查询耗时从25ms降低到6ms,下降75%。日志集群升级JDK17后,写入性能提升15~20%,解决写入队列堆积和 reject 问题。
ES JDK17的升级,详情见:《解锁滴滴ES的性能潜力:JDK 17和ZGC的升级之路》
成本优化
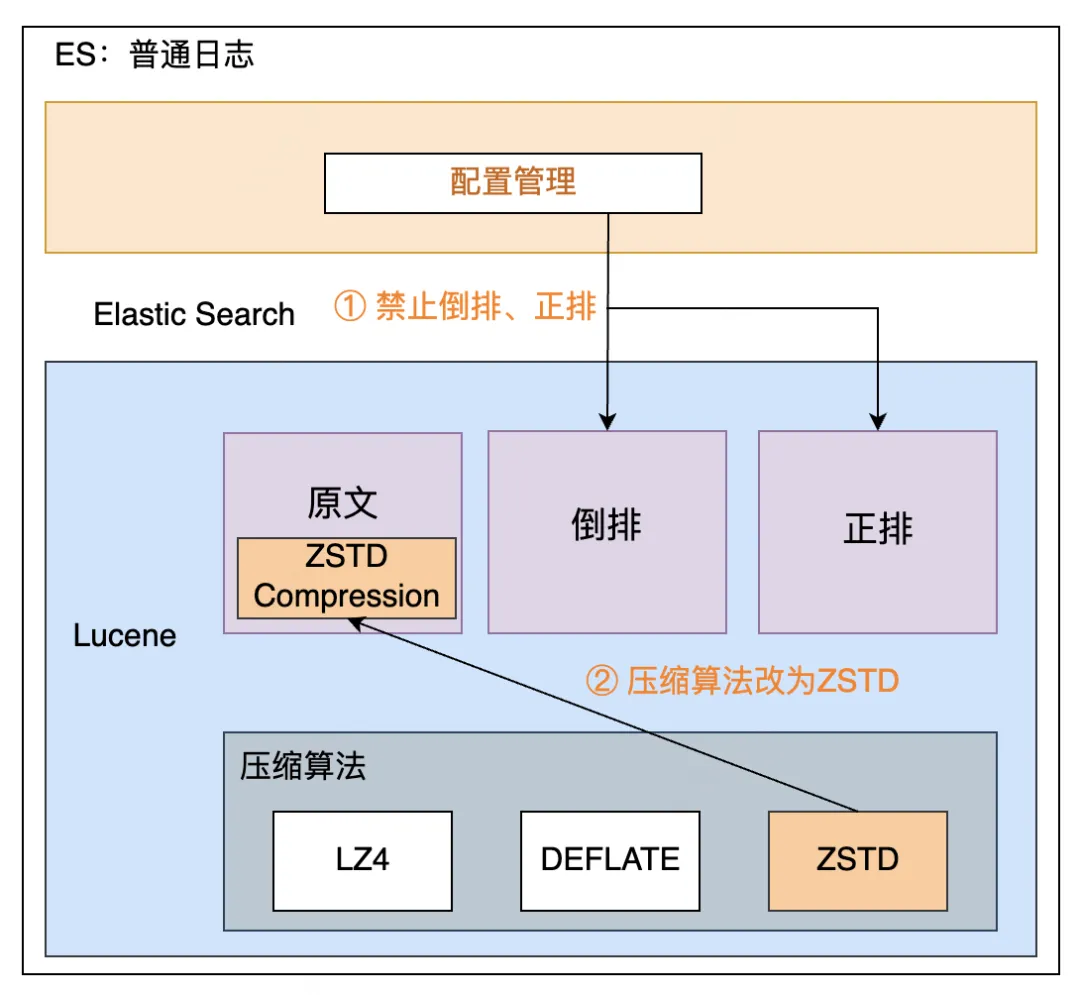 成本优化主要包括降低机器成本和降低用户成本。
成本优化主要包括降低机器成本和降低用户成本。
降低机器成本核心是降低存储规模和降低 CPU 使用率,即降低机器数;降低用户成本的核心逻辑是降低业务用量,所以 ES 整体成本优化策略如下:
- 索引 Mapping 优化,禁止部分字段倒排、正排
- 新增 ZSTD 压缩算法,CPU 降低15%
- 接入大数据资产管理平台,梳理无用分区和索引,协助业务下线
关于 ES 支持 ZSTD 的实现,详情见:《如何让ES低成本、高性能?滴滴落地ZSTD压缩算法的实践分享》
多租户资源隔离
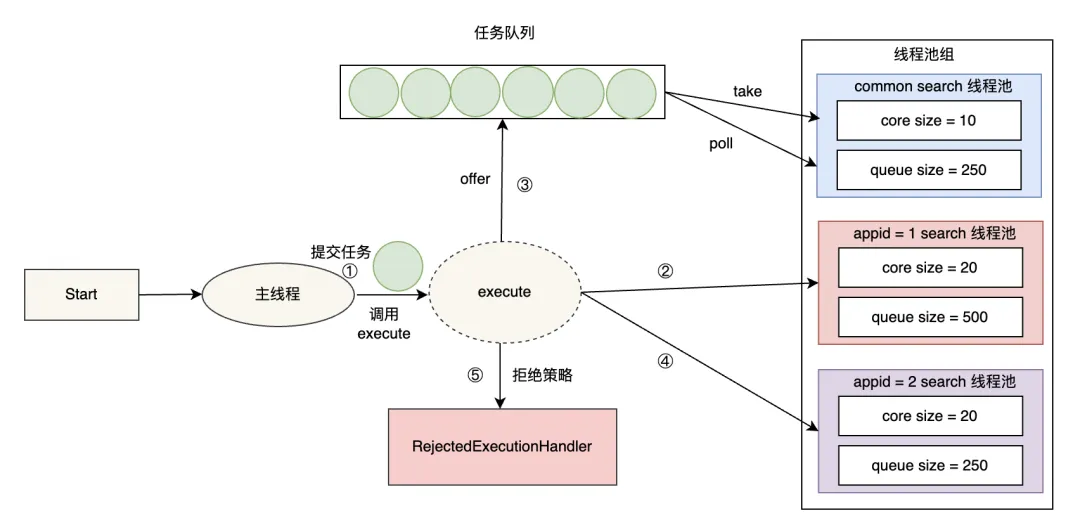
JDK原生线程池模型:
- 主线程调用 execute、或者 submit 等方法提交任务给线程池。
- 如果线程池中正在运行的工作线程数量小于 corePoolSize(核心线程数量),那么马上创建线程运行这个任务。
- 如果线程池中正在运行的工作线程数量大于或等于 corePoolSize(核心线程数量),那么将这个任务放入队列,稍后执行。
- 如果这时队列满了且正在运行的工作线程数量还小于 maximumPoolSize(最大线程数量),那么会创建非核心工作线程立刻运行这个任务,这部分非核心工作线程空闲超过一定的时间(keepAliveTime)时,就会被销毁回收。
- 如果最终提交的任务超过了 maximumPoolSize(最大线程数量),那么就会执行拒绝策略。
我们借鉴了 Presto Resource Group 隔离的思路,策略是将原来的 search 线程池按照配置拆分为多个 seach 线程池并组建线程池组。由于多租户的查询 QPS、重要等级不同,可以配置相应的线程数量和队列大小。通过线程池组模式,隔离不同 Appid 用户的查询请求。
 核心工作流程为获取 Appid,根据配置的Appid隔离信息将任务提交到对应的子线程组中运行。
核心工作流程为获取 Appid,根据配置的Appid隔离信息将任务提交到对应的子线程组中运行。
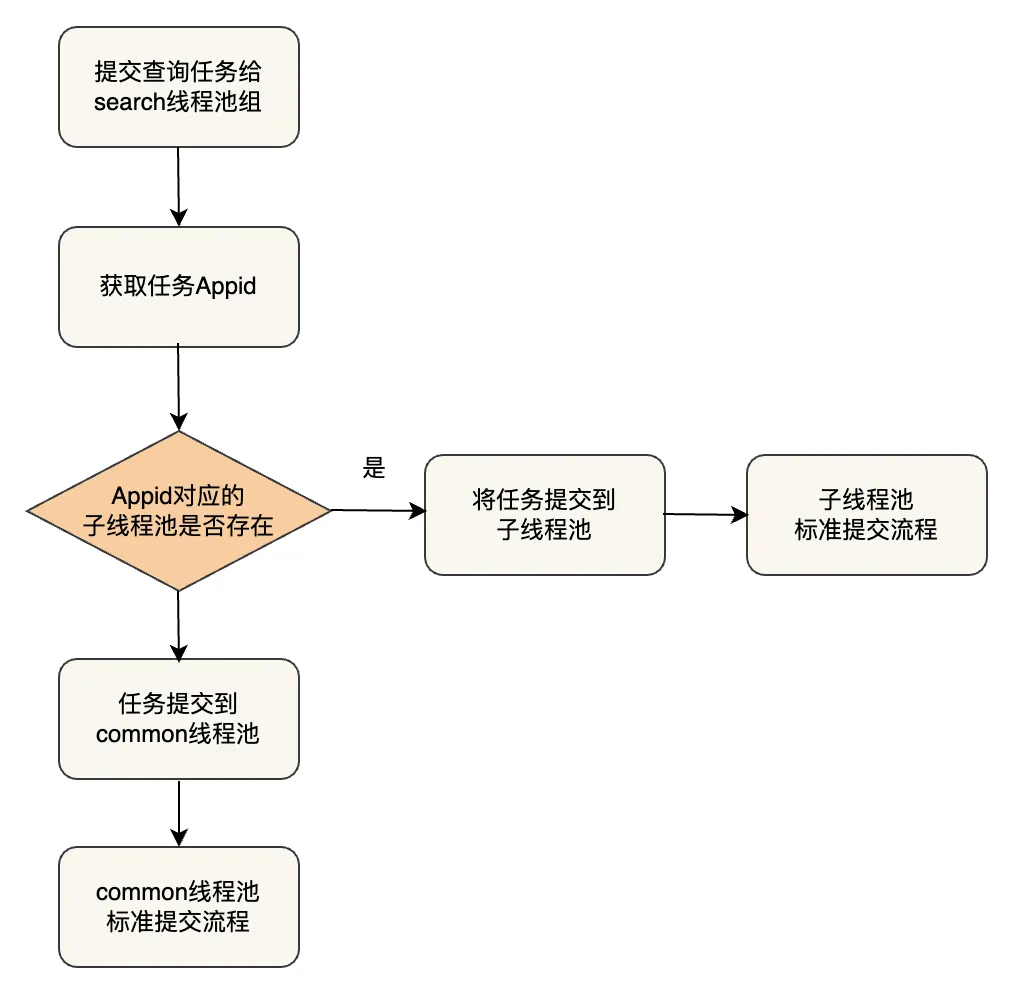 目前此优化主要用于一份索引数据会被很多个业务方使用的场景,如订单业务,订单业务会被公司各个业务线使用,所以查询 appid 会非常多,我们通过多租户资源隔离限制指定 Appid 的线程池大小,避免由于某业务突然发送大量读请求导致 CPU 打满,核心业务受损。
目前此优化主要用于一份索引数据会被很多个业务方使用的场景,如订单业务,订单业务会被公司各个业务线使用,所以查询 appid 会非常多,我们通过多租户资源隔离限制指定 Appid 的线程池大小,避免由于某业务突然发送大量读请求导致 CPU 打满,核心业务受损。
数据安全
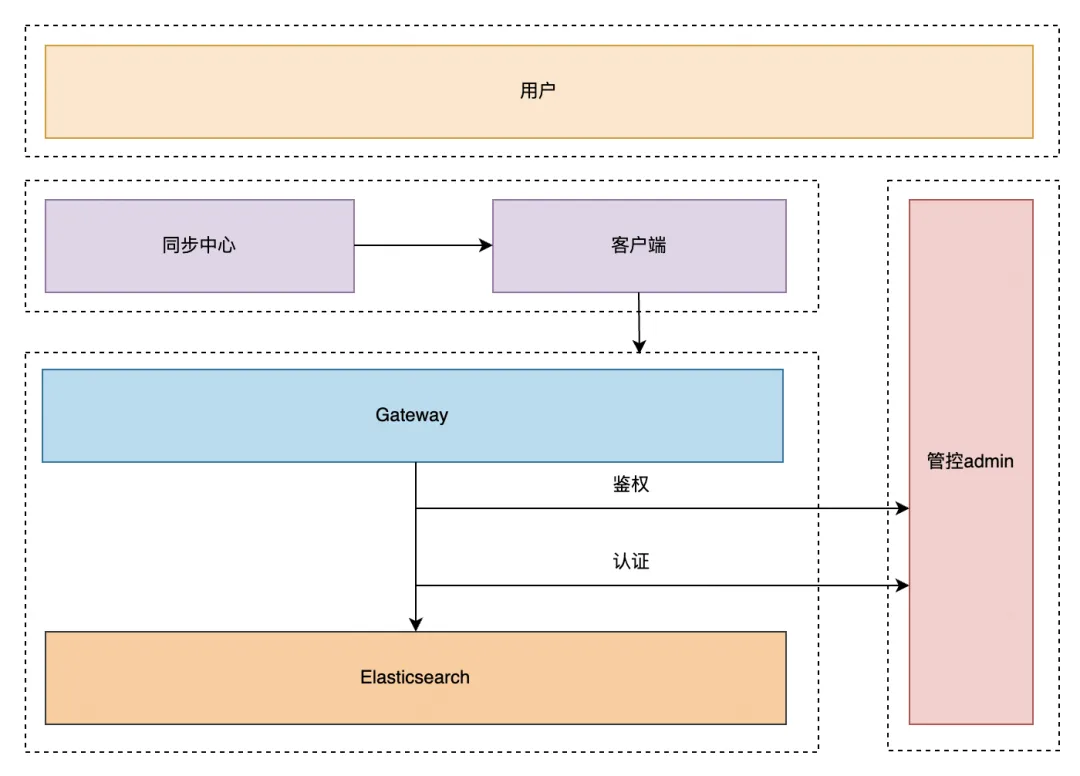 两种级别的鉴权和认证:
- Gateway 级别:主要是 Appid 级别的鉴权
- ES 级别(Clientnode、Datanode、MasterNode),主要是做认证
两种级别的鉴权和认证:
- Gateway 级别:主要是 Appid 级别的鉴权
- ES 级别(Clientnode、Datanode、MasterNode),主要是做认证
ES 的 X-Pack 插件是有安全认证能力的,但是不支持集群滚动升级重启,无法快速回滚,误删存储有稳定性风险,基于此我们自研了一个安全插件,优势:
- 架构简单,逻辑清晰,只需在 HTTP 请求处理环节中进行简单的字符串校验,无需涉及节点内部 TCP 通信验证。
- 支撑 ES 集群滚动重启升级
- 支持一键开关安全认证能力,可以快速止损
关于ES安全认证方案,详情见:《数据安全加固:深入解析滴滴ES安全认证技术方案》
稳定性治理
在线文本检索对稳定性要求非常高,所以过去的三年,我们稳定性方面主要做了如下图所示的以下工作: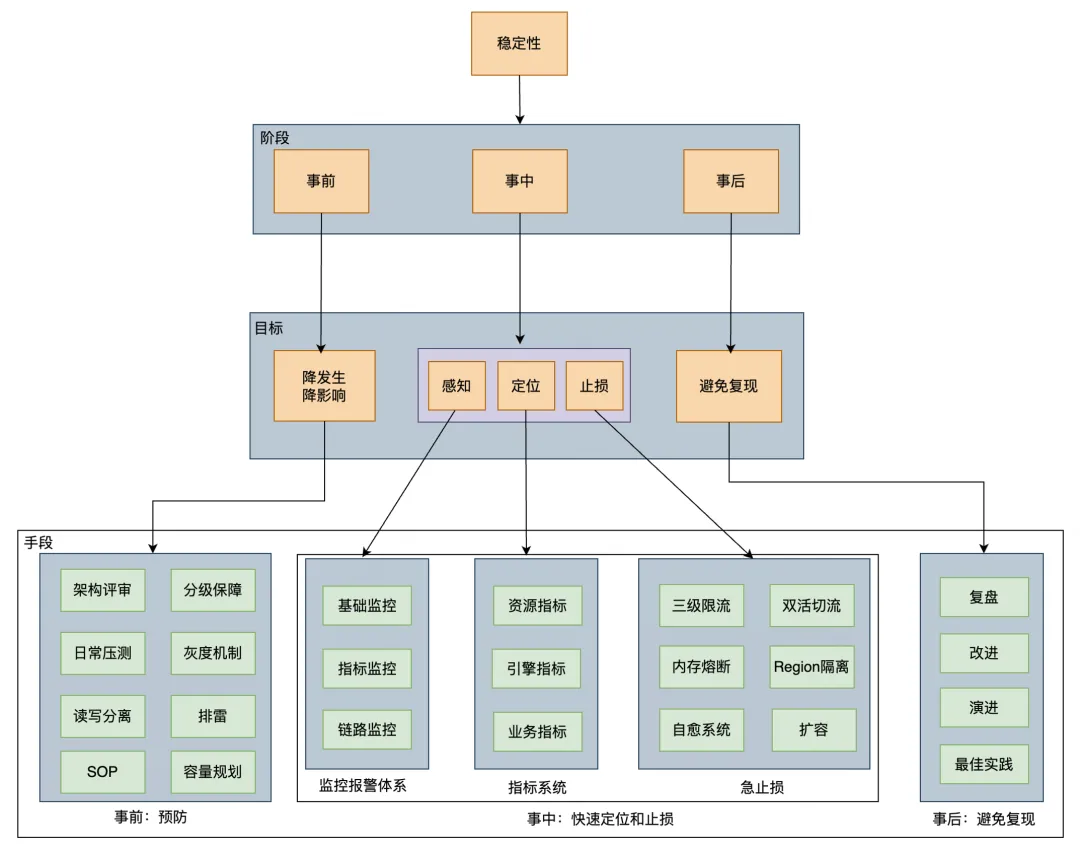
稳定性治理主要是做好三件事:事前、事中和事后。事情预防为主,事中能够快速定位和止损,事后注重复盘,避免问题重复出现,
- 事前预防为主,持续优化:我们每年都会把稳定性当做最重要的事情去做,规范先行,落实稳定性红线,包括方案设计、代码规范、上线规范、报警处理及故障管理等。每年都会执行稳定性“扫雷”专项,三年时间我们共解决了61个稳定性隐患,如解决 Gateway Full GC 问题(业务限流后,Gateway会立马恢复正常),元数据治理,重写部分锁解决 ThreadLocal 泄露(ThreadLocal 泄露会导致部分节点突然 CPU 飙升)等,同时落地故障止损SOP
- 监控报警体系建设,我们做了基础监控(如硬盘、CPU等),指标监控(如shard数,master pending task 个数等),链路监控(监控 MQ Lag,提前发现链路延时问题)
- 指标系统建设,通过 grafana 建设了监控大盘,包括模版指标,shard 指标,节点指标及集群指标等,这些指标能够协助我们快速定位故障原因,如 CPU 突增问题,我们可以做到5分钟内快速止损
- 止损侧我们做了自愈系统(如磁盘故障,查询突增),日常双活切流演练,读写限流等,其中读限流做了基于 Appid、索引模板和查询DSL的限流,当出现集群 CPU 突增问题时,限流方案也会尽可能降低对业务的影响
总结与展望
近年来,我们基于 ES 7.6.0 版本,围绕保稳定、控成本、提效能和优生态方面进行了持续的探索和改进。目前,我们的 ES 引擎已在滴滴内部统一应用于所有在线检索场景,并在稳定性方面成为大数据架构部的标杆。
我们还尝试过一些创新方案,如冷热数据分离、离在线混合部署以及使用 Flink Checkpoint 机制替代 Translog 等,但由于性能或稳定性等方面的考虑,这些方案并未被采纳。然而,随着技术的不断发展,我们将继续探索和完善这些方案,以应对未来可能出现的挑战。
目前,我们使用的 ES 版本是 7.6,而社区的最新版本已经更新至 8.13,两者之间存在约 4 年的版本差距。因此,我们今年的重点工作是将 ES 平滑升级至 8.13 版本,以解决以下问题:
- 新版本的 ES Master 性能更优
- 能够根据负载自动平衡磁盘使用
- 减少 segment 对内存的占用
- 支持向量检索的 ANN 等新特性
在性能方面,我们将针对更新场景优化写入性能,同时改进查询过程中的 Merge 策略。此外,我们还将持续探索新版本 ES 的机器学习能力,以便更好地为业务提供支持。