前言
好几年前的文章了,之前排查问题,随手写的,但是发现其他团队人遇到类似问题没有思路,所以还是发出来,给大家一起解决问题的思路。
问题描述
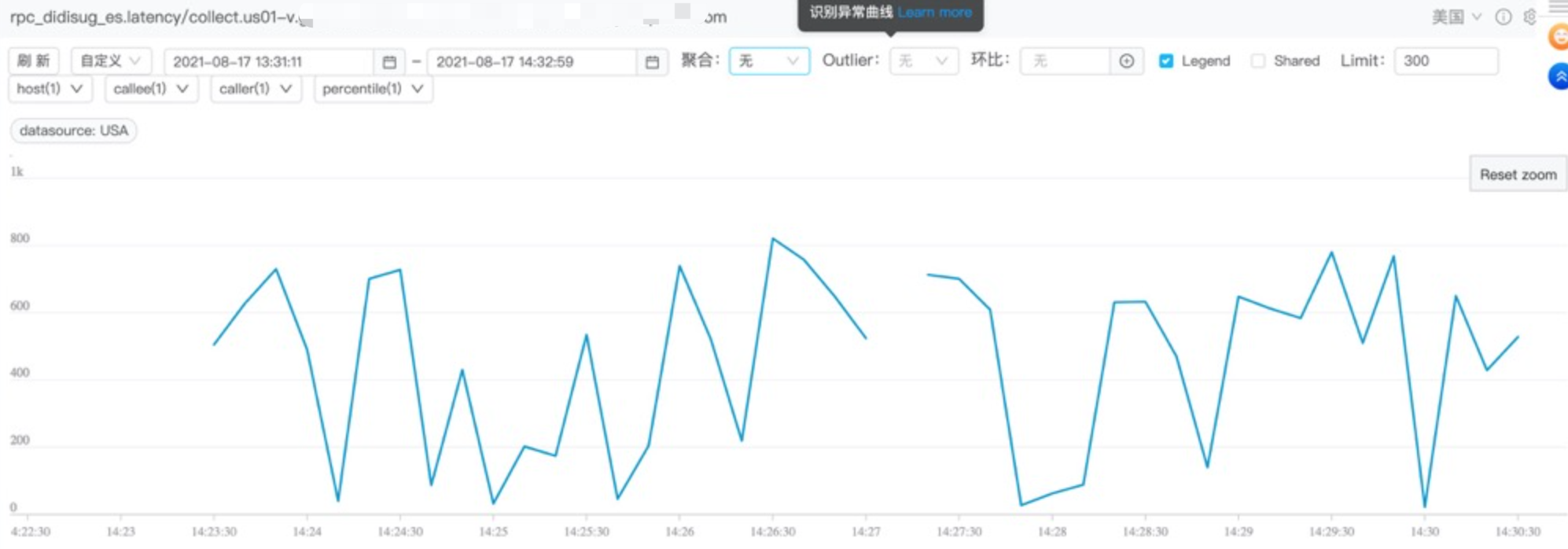
ES集群磁盘报警,发现/home/coresave/ core文件导致根目录磁盘被打满,删除core文件恢复,已知这个集群新上线了jdk 17 zgc,排查下jvm为啥core。而jvm core一般有以下几个原因:资源超了(内存、线程数,vma数等),jvm bug(比如指令集)
排查过程
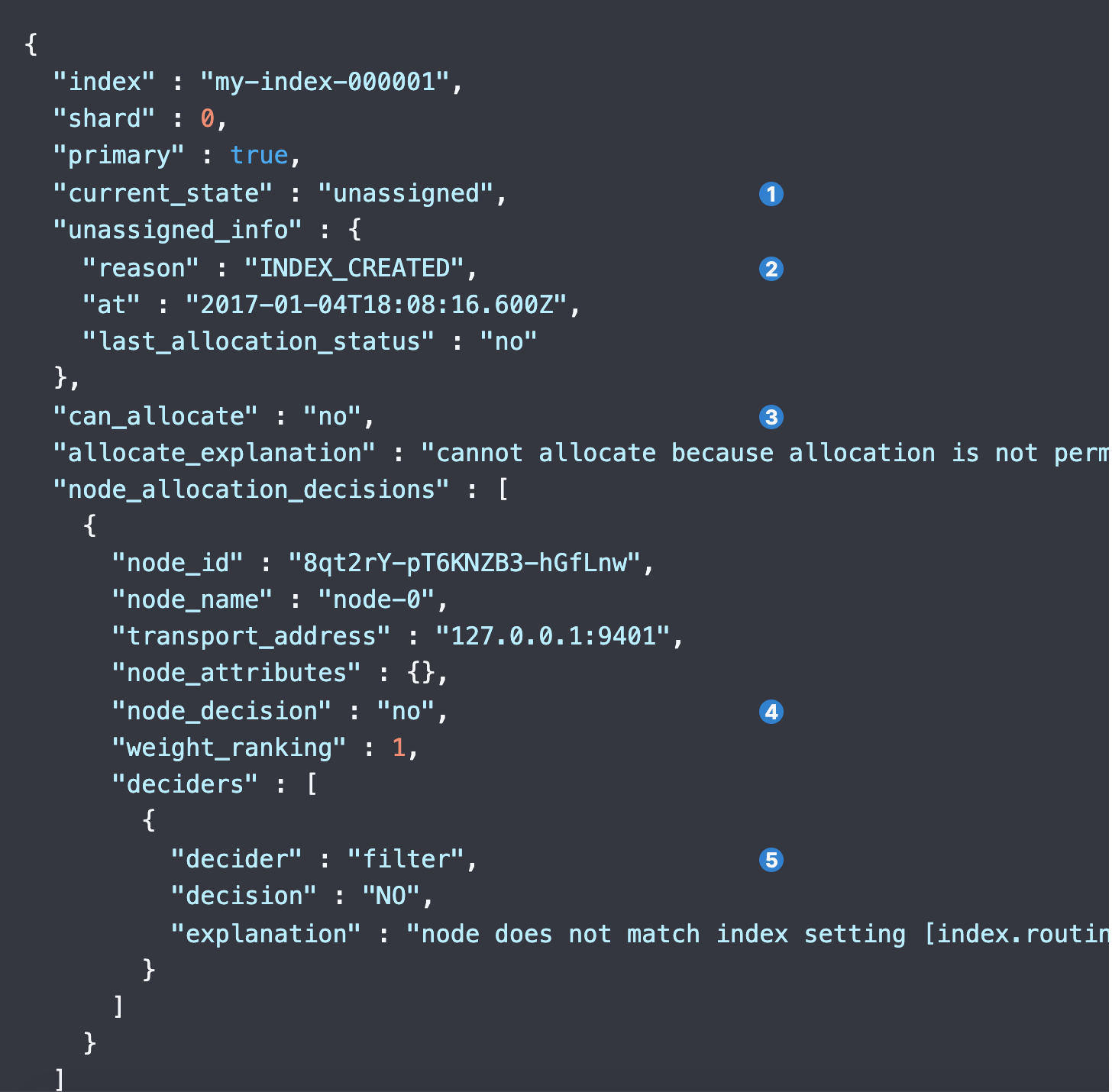
先去elasticsearch根目录查看core日志,即hs_err_pid_xxx.log,内容如下:
看core原因是因为资源不足(不一定是内存)导致的问题,jdk 17 zgc core后,fatal error 原因与g1 有明显不同,突然不知道怎么去排查了,研究下,思路如下。资源不足原因我们可以在hs_err.log里查看具体的原因,步骤如下:
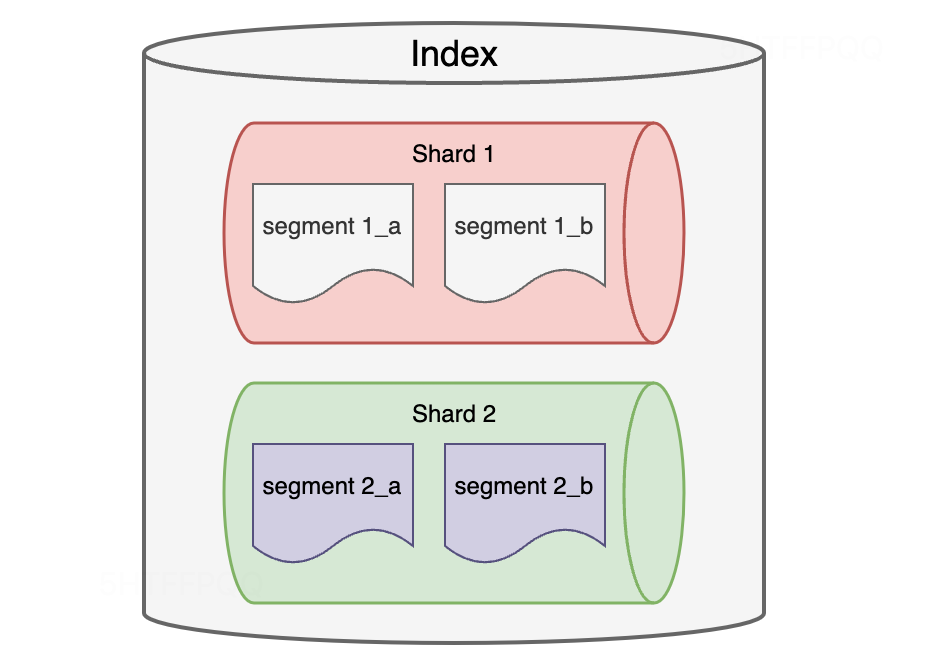
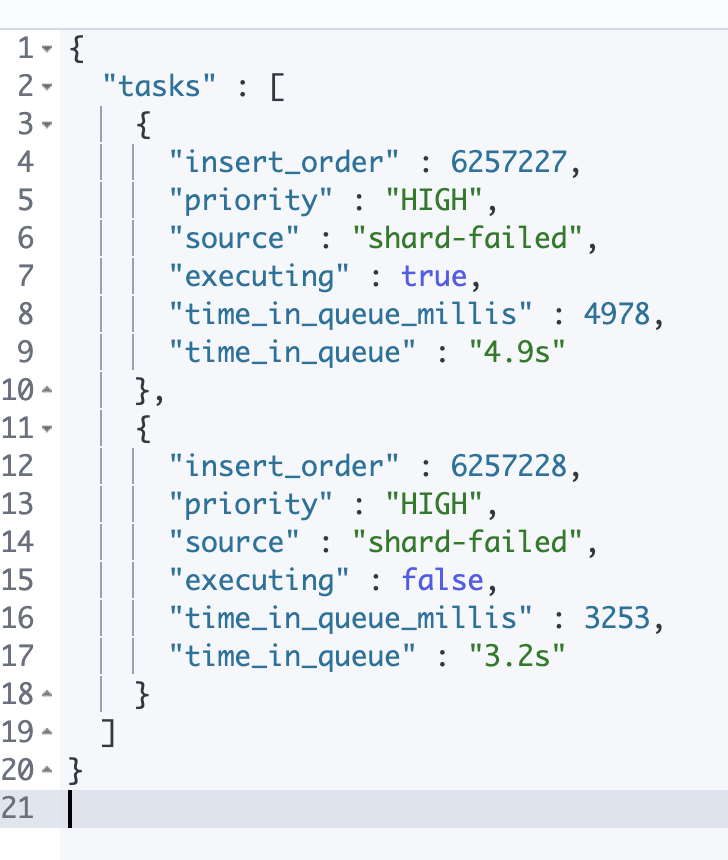
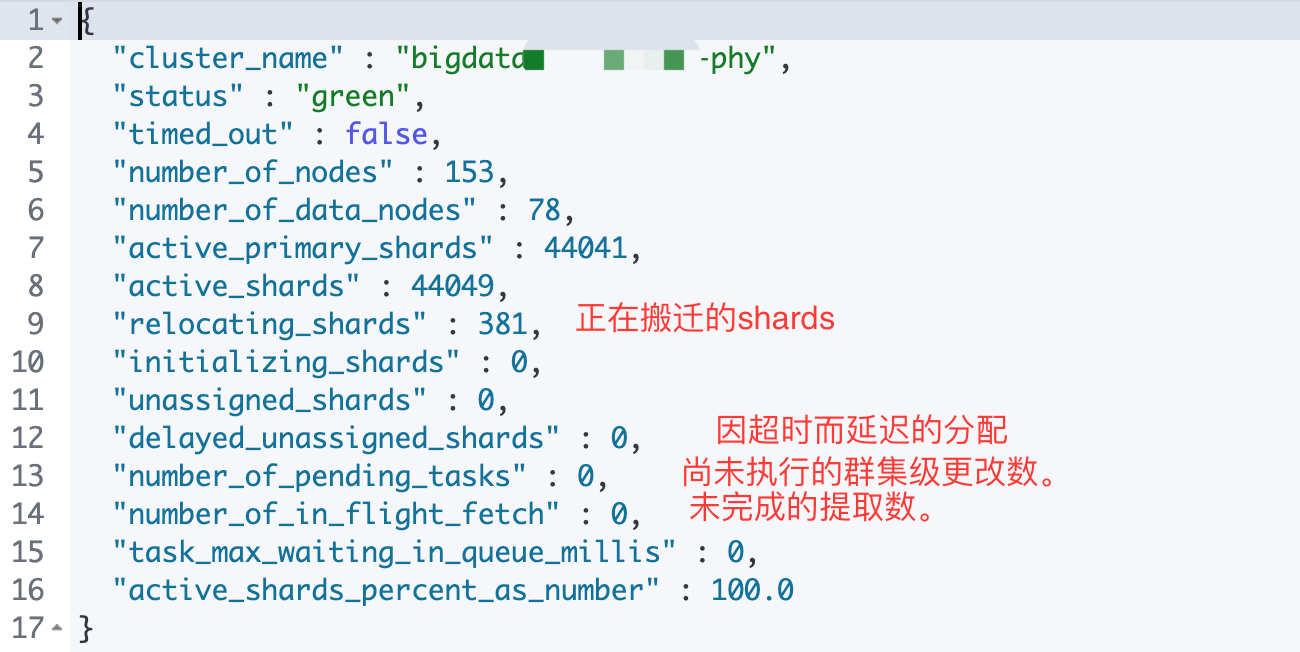 number_of_pending_tasks:是指主节点创建索引并分配shards等任务,如果该指标数值一直未减小代表集群存在不稳定因素 。
number_of_pending_tasks:是指主节点创建索引并分配shards等任务,如果该指标数值一直未减小代表集群存在不稳定因素 。