在维护 OLAP 引擎时,很多时候需要对引擎做系统的性能分析和优化,此时往往需要查看 CPU 耗时,了解主要耗时点及瓶颈在哪里。俗语有曰:兵欲善其事必先利其器,程序员定位性能问题也需要一件“利器”。性能调优工具(perf)能够显示系统的调用栈及时间分布,但是呈现内容上只能单一的列出调用栈或者非层次化的时间分布,不够直观。火焰图(flame graph)能够帮助大家更直观的发现问题。本文将以 Presto 为例,介绍火焰图的使用技巧。
初识火焰图
Perf 的原理是这样子的:每隔一个固定的时间,就在 CPU 上(每个核上都有)产生一个中断,在中断上看看,当前是哪个 pid,哪个函数,然后给对应的 pid 和函数加一个统计值,这样,我们就知道 CPU 有百分几的时间在某个 pid,或者某个函数上了。而火焰图(Flame Graph)是由 Linux 性能优化大师 Brendan Gregg 发明的,和所有其他的 profiling 方法不同的是,火焰图以一个全局的视野来看待时间分布,它从底部往顶部,列出所有可能导致性能瓶颈的调用栈。
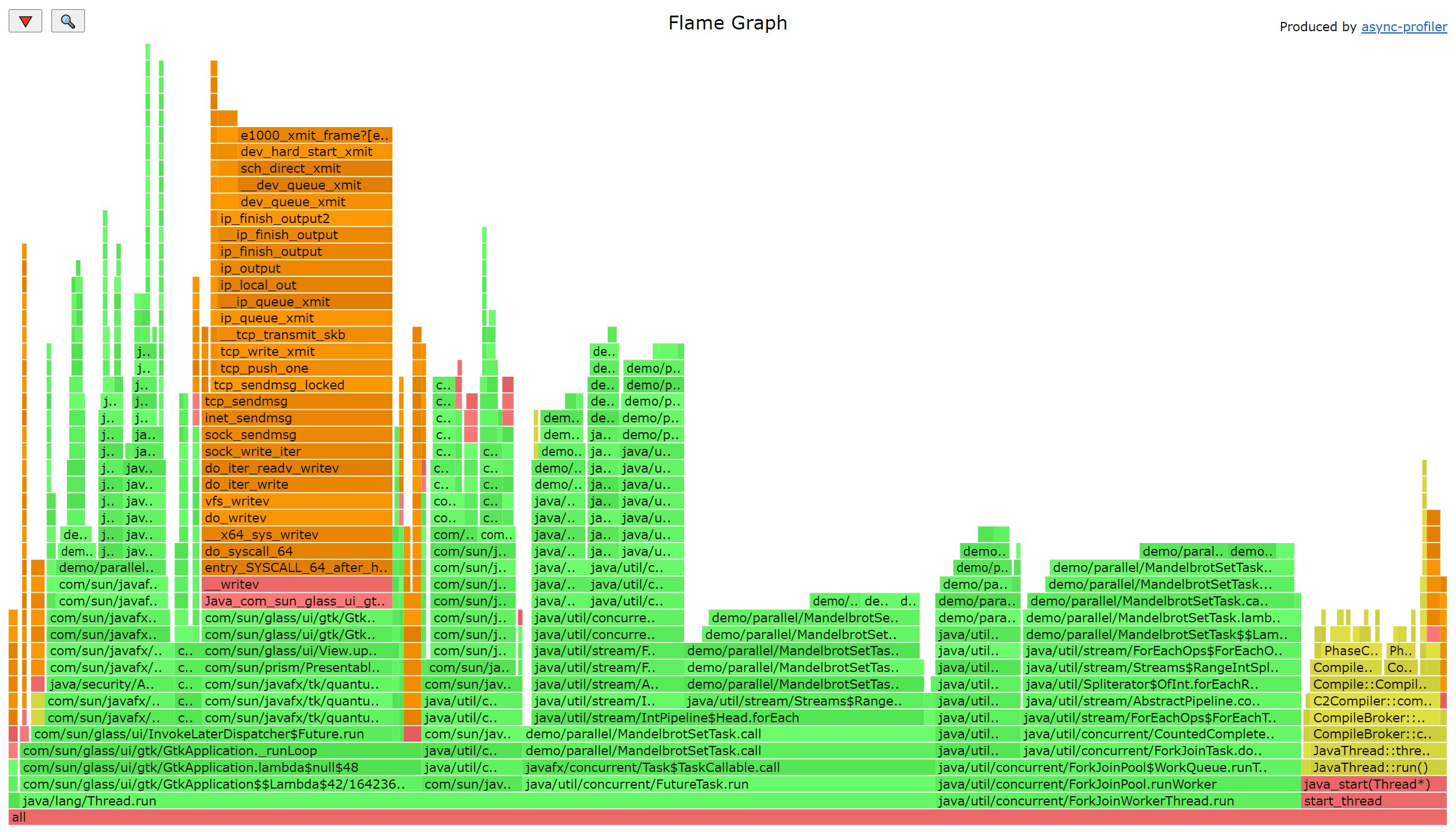
火焰图整个图形看起来就像一个跳动的火焰,这就是它名字的由来。火焰图有以下特征(这里以采样CPU 火焰图为例):
- 每一列代表一个调用栈,每一个格子代表一个函数。
- 纵轴展示了栈的深度,按照调用关系从下到上排列。最顶上格子代表采样时,正在占用 CPU 的函数
- 横轴的意义是指:火焰图将采集的多个调用栈信息,并行关系。横轴格子的宽度代表其在采样中出现频率,所以一个格子的宽度越大,说明它是瓶颈原因的可能性就越大。
- 火焰图格子的颜色是随机的暖色调,方便区分各个调用信息。
- 其他的采样方式也可以使用火焰图, 比如内存
所以,火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”,就表示该函数可能存在性能问题,也是我们性能优化收益最大的地方。
Java生态常见的用于perf的工具有:allocation-instrumenter、YourKit Profiler、async-profiler、JProfiler、Arthas(基于 async-profiler )。笔者推荐使用阿里巴巴出品的 Arthas 或 async-profiler,笔者喜欢使用 async-profiler 这个 perf 工具生成火焰图,主要原因是用法简单,足够满足日常排查性能问题了。
async-profiler 介绍
Async-profiler是一款没有 Safepoint bias problem 的低开销 Java 采集分析器,它的实现是基于HotSpot 特有的 API,通过这些特有的 API 收集堆栈跟踪和跟踪内存分配,因而其可以和 OpenJDK、Oracle JDK 和其他基于 HotSpot JVM 的 Java 应用在运行时协同工作。
Async-profiler 可以跟踪以下类型的事件:
- CPU 周期;
- 硬件和软件性能计数器,如 cache misses, branch misses, page faults, context switches 等;
- Java 堆中的分配;
- 锁尝试,包括 Java 对象监视器和可重入锁;
支持的平台 - Linux / x64 / x86 / ARM / AArch64
- macOS / x64
并且 IntelliJ IDEA Ultimate 2018.3 之后的版本也集成了 async-profiler。Github 项目链接地址:https://github.com/jvm-profiling-tools/async-profiler
主页上有已经编译好的包,找到对应的平台下载即可:
async-profiler 使用
下载好的文件解压后,有一个profiler.sh脚本,运行脚本即可对 Java 进程进行 CPU 分析。例如 Presto 的 Java 进程 id 为 8983。
1 | jps |
或者可以用-d指定剖析的时间(秒),我们将其重定向到一个文本文件里。
1 | ./profiler.sh -d 30 8983 > 8983.txt |
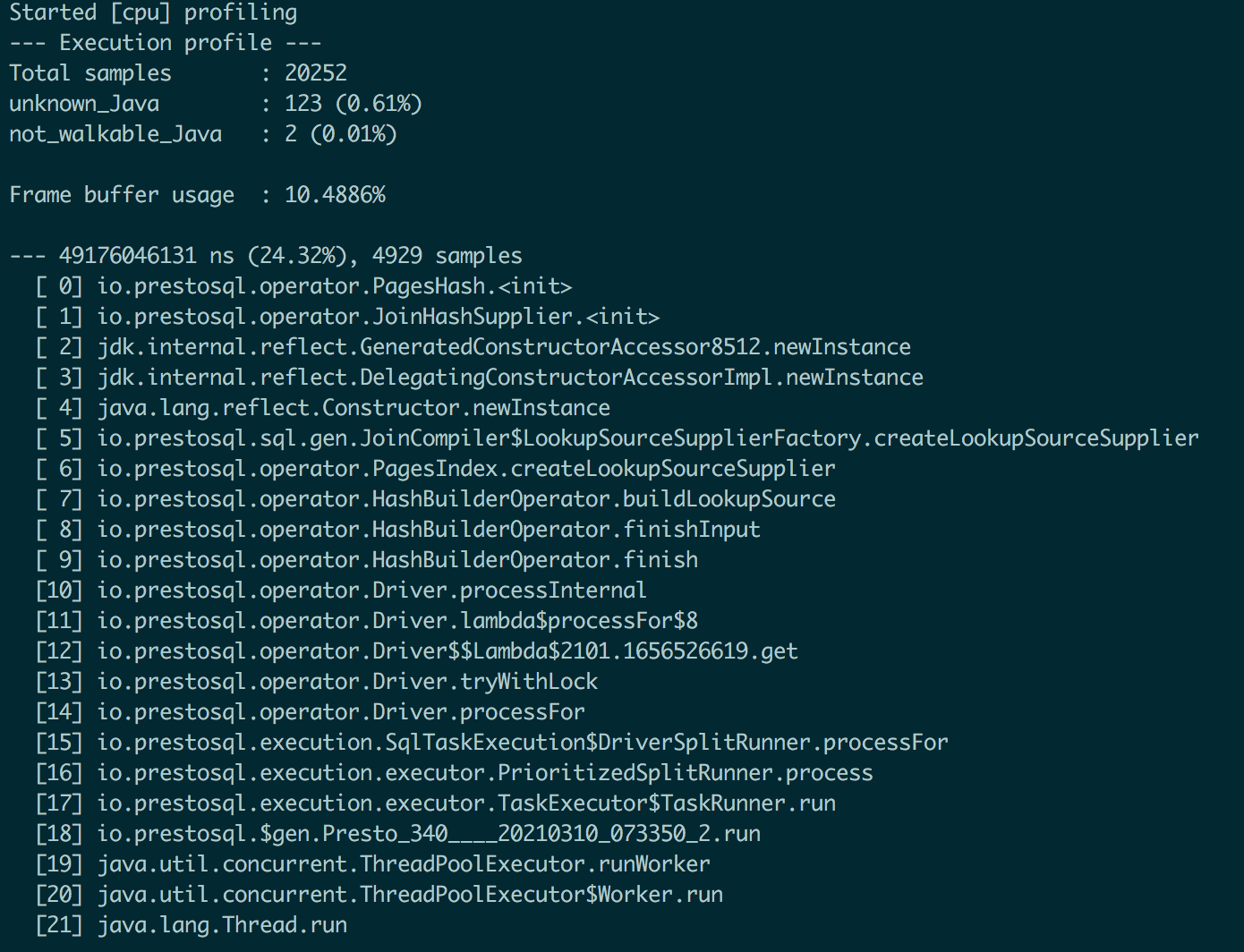
执行完成后会输出采集的信息,这些信息可以帮我看到详细的函数调用逻辑,这非常有用,因为假如你新接触一个新的 OLAP 引擎,想快速入门,比如想了解其读写流程及代码执行流程,通过这些采集信息就可以快速帮我们捋清楚执行流程,如下:
如果你想生成火焰图,只需要执行如下命令即可:
1 | ./profiler.sh -d 30 -f /tmp/flamegraph.svg 8983 |
生成的svg火焰图如下图所示:
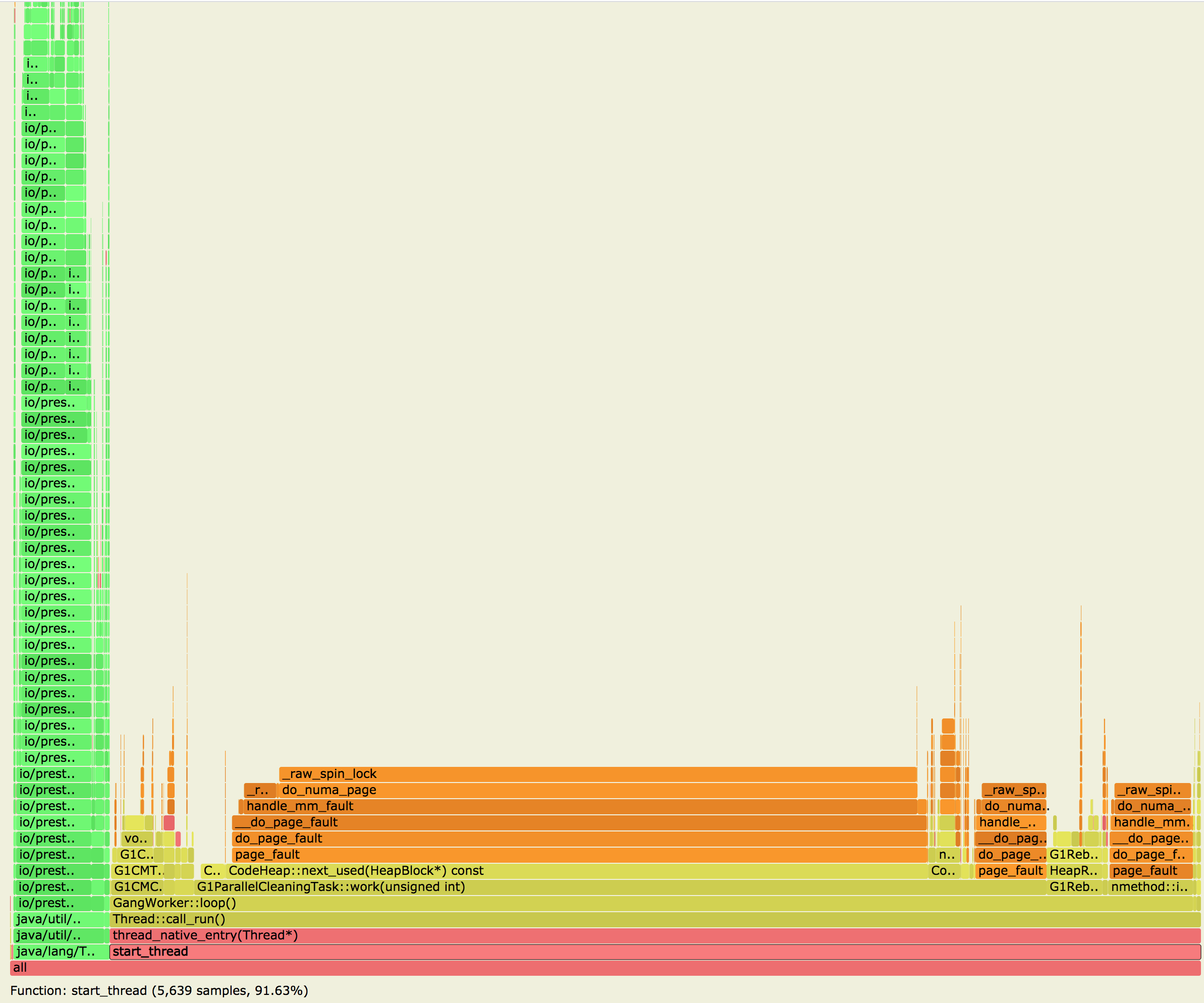
从上图我们可以看到大约 91.63% 的CPU用于GC,如果当前系统 CPU 使用率比较高,那就说明这些 CPU 没有在干正事,都耗费在 GC 里了,当前服务的主要瓶颈在 JVM 层,需要找下 JVM 瓶颈。
event 参数介绍
event 可选参数使用如下命令查看,不同 CPU 支持的 event 是不一样的。
1 | ./profiler.sh list list 8983 |
输出结果:
1 | [presto@localhost ~]$ ./profiler.sh list list 8983 |
event 默认为 cpu ,假如想查看内存分配,可以使用 alloc 查看,命令如下:
1 | ./profiler.sh -e alloc -d 30 -f /tmp/flamegraph.svg 8983 |
火焰图如下:
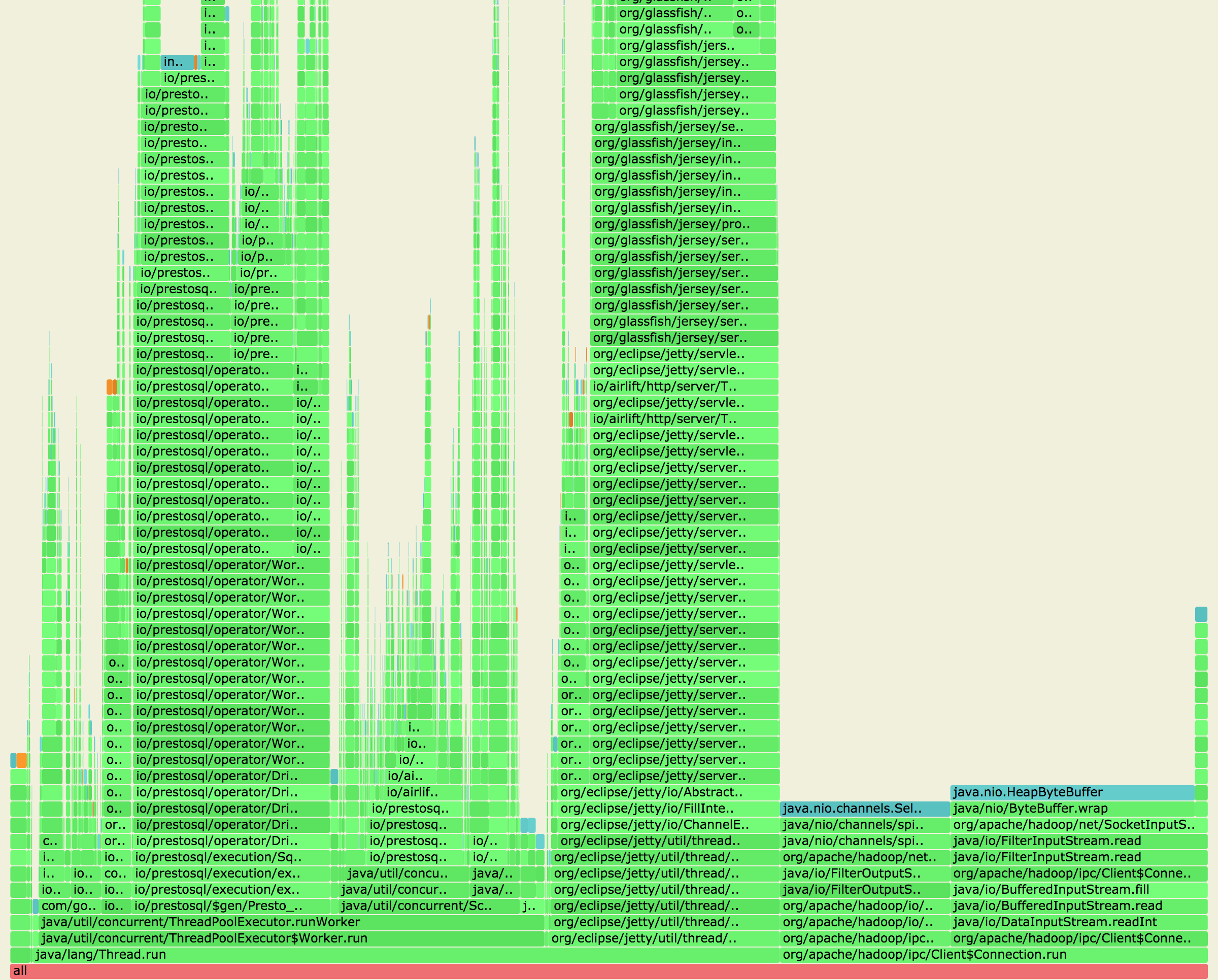
如上图所示,可以看到内存占用主要包括三大部分:Presto执行、数据交互及读取HDFS,知道这些信息后,我们就可以针对性的优化了。
使用过程中常见的问题
在使用 Async-profiler 过程中,我们有时候会遇到如下错误:
1 | Could not start attach mechanism: No such file or directory |
这是因为 Java 程序第一次执行 jmap 或 jstack 等 perf 命令后会在 /tmp 下创建 socket 文件,socket 文件路径为 /tmp/.java_pidXXX,但是操作系统默认 10 天会删除这个临时文件,之后再执行 perf 命令就不行了,解决方法是在 /usr/lib/tmpfiles.d/tmp.conf 中添加 x /tmp/.java* ,这样就不会删除这个 socket 文件了。
参考资料: