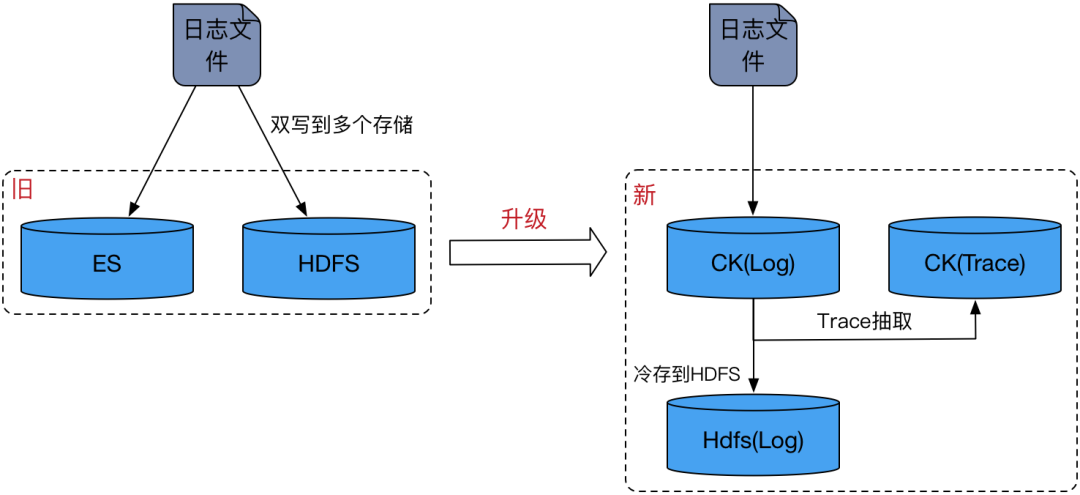
背景
过去滴滴内部基于自研的日志采集 Agent,构建了覆盖全链路的实时日志采集体系。依托分布式架构设计,每日稳定处理数 PB 级超大规模日志数据,实现对集团内部业务应用的高并发、低延迟日志采集支持,为全公司业务监控、故障诊断、数据分析等场景提供了可靠的底层数据基础设施。
随着AMD机器(核数大幅增加)的引入,面对超大流量采集,原内部Agent逐渐力不从心。经过调研发现iLogTail的架构和性能更契合需求,因此我们决定将内部Agent升级到开源iLogTail,并基于开源版本进行了大量优化。
iLogTail简介
iLogTail是阿里云SLS于2022年6月开源的采集器项目,在阿里巴巴以及外部数万家阿里云客户内部广泛应用,装机量近千万,每天采集数十PB可观测数据。
iLogTail具有轻量级、高性能、低延迟等特点,相比竞品Agent,整体的资源开销、采集性能、以及采集延迟都有一个比较大的优势。
iLogTail架构
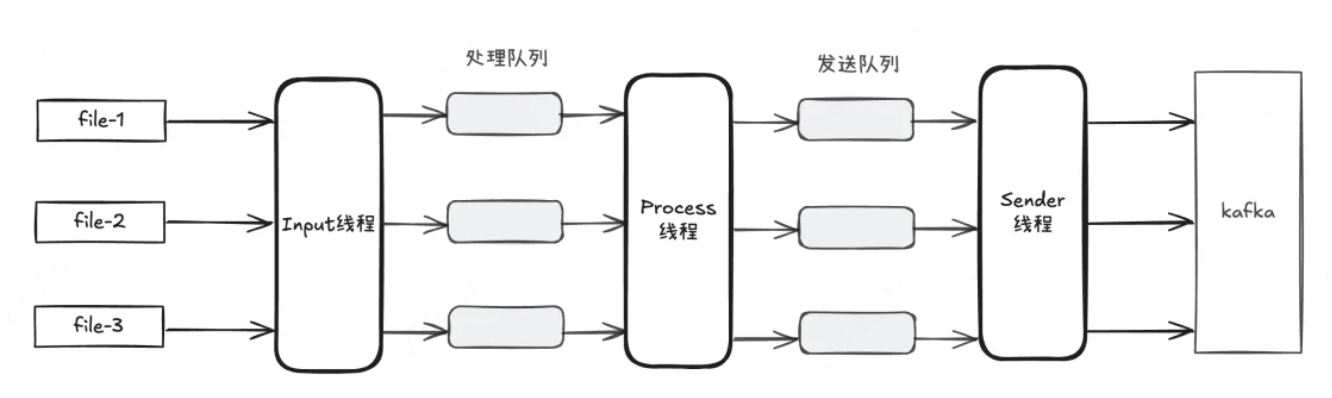
iLogTail架构更像一个集中式架构,每个采集任务的输入模块、处理模块和发送模块都共享一组线程资源,线程之间通过缓冲队列来交换数据。相较于单体架构(每个任务都有独立的线程资源),这种架构在代码实现上会更加复杂,需要自己去管理任务的调度,资源管控等等,但从性能的角度出发,却能极大地节省资源和提升效率。
iLogTail优势
- 高效采集,通过Linux操作系统inotify的一个机制,感知到目录或文件的变化后,立刻进行相关的采集,借助inotify,Logtail有更低延迟和更低的性能消耗。
- 高性能,iLogTail的采集部分及发送到SLS部分是C++编写的,C++部分拥有很高的性能,iLogTail还拥有很丰富的插件但这些都是通过Go编写,如发送到Kafka的插件,Go部分拥有功能优势,但是其垃圾回收会带来很大性能消耗,后面会针对这部分进行优化。
性能优化
在测试iLogTail的过程中,开源版本的性能并不能满足滴滴内部的需求,下面将介绍在iLogTail上的性能优化。
多行解析
多行解析指的是从日志中读取数据时,遇到带有异常堆栈的这种多行日志,需要解析合并成一行日志。
社区是通过配置正则表达式来实现的,在读取的时候正则匹配每一行数据,来判断是否属于同一行日志,这种正则匹配的方式可以适用于任何场景,但是带来的性能下降却很严重。
为解决这一问题,我们实现了基于时间规则的多行解析方法。通过解析每行日志中的时间戳,判断日志是否属于异常堆栈(异常堆栈通常不包含时间戳)。若某行日志的时间戳无法成功解析,则将其与前一行合并,从而实现对异常堆栈的准确识别与整合。
基于时间的多行解析相对于正则匹配可以减少大量字符比较,大大的提升了解析性能,优化后处理速度可以提升1倍。
在此基础之上,还引入AVX2指令集,通过向量化来解析换行符,一条指令操作32个字符。

优化之前多行解析中耗时主要集中在 GetNextLine 和 ParseTime :
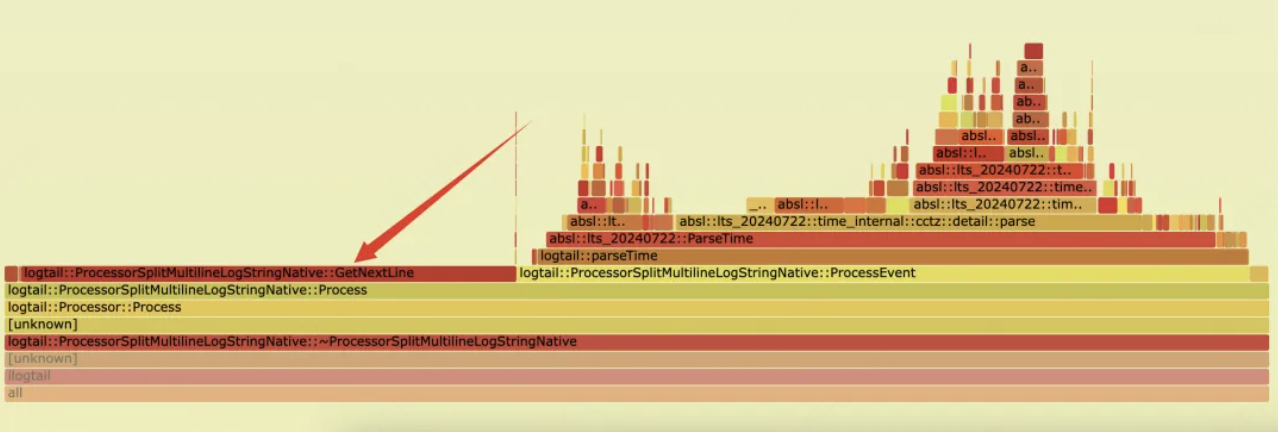
优化后GetNextLine耗时大大缩短: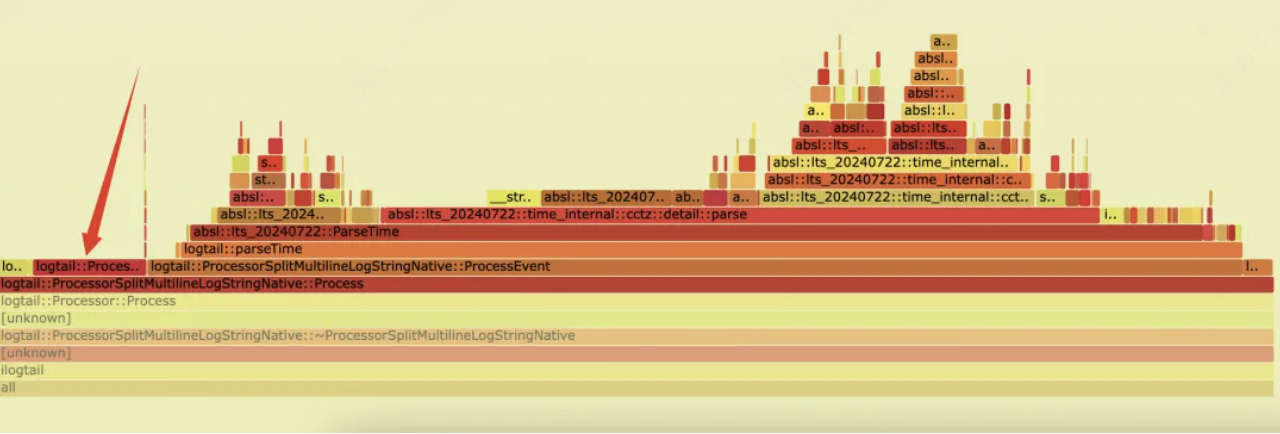
通过向量化优化后CPU性能可以提升8%。
C++重写FlusherKafka插件
在AMD机器上进行大流量(100+MB/s)测试时,发现性能急剧下降,开始出现大面积采集延迟,通过打印火焰图分析看到60%以上的CPU都花在垃圾回收上。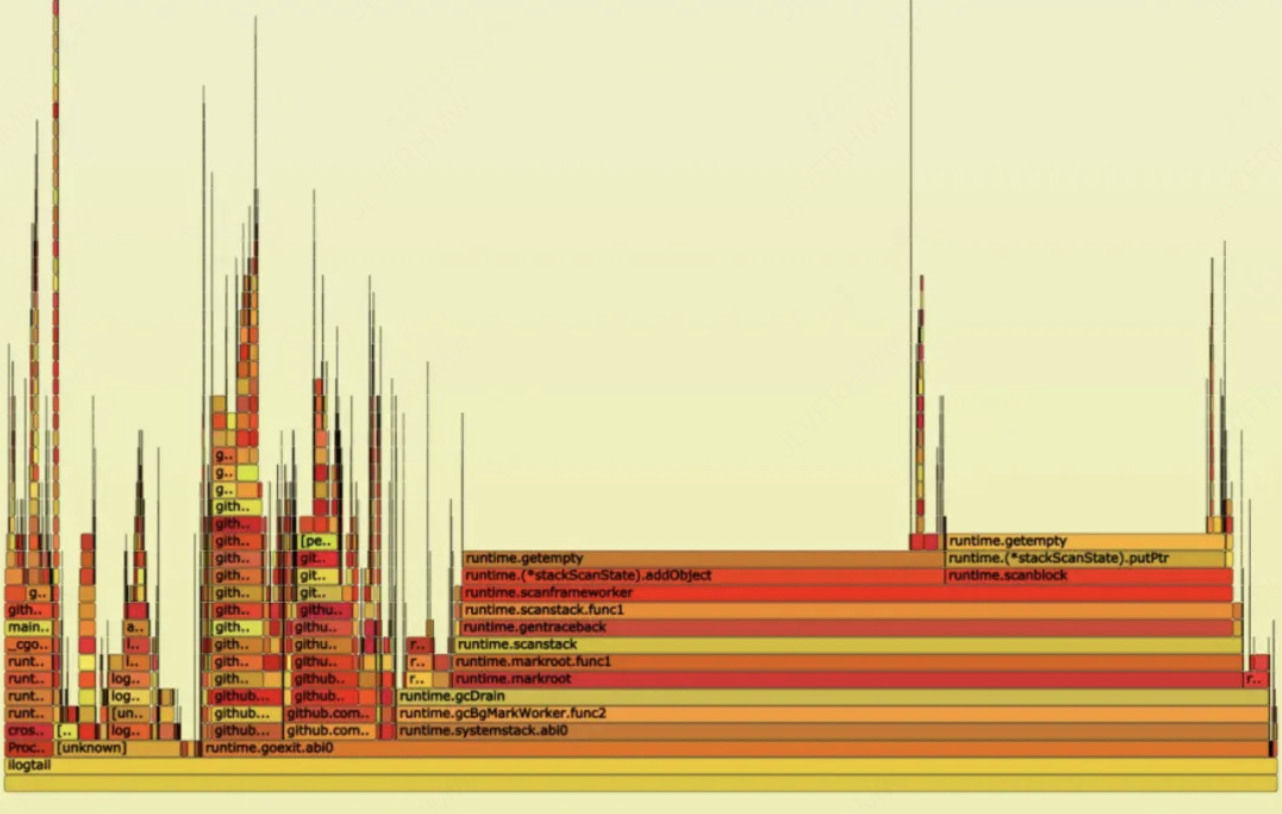
在日志采集的场景中,大量日志对象的频繁创建和销毁会对 Go GC的性能产生很大的压力。
最初通过调大Go的堆内存和关闭触发堆GC,性能有所好转,但继续增加流量,频繁GC的问题仍会出现。
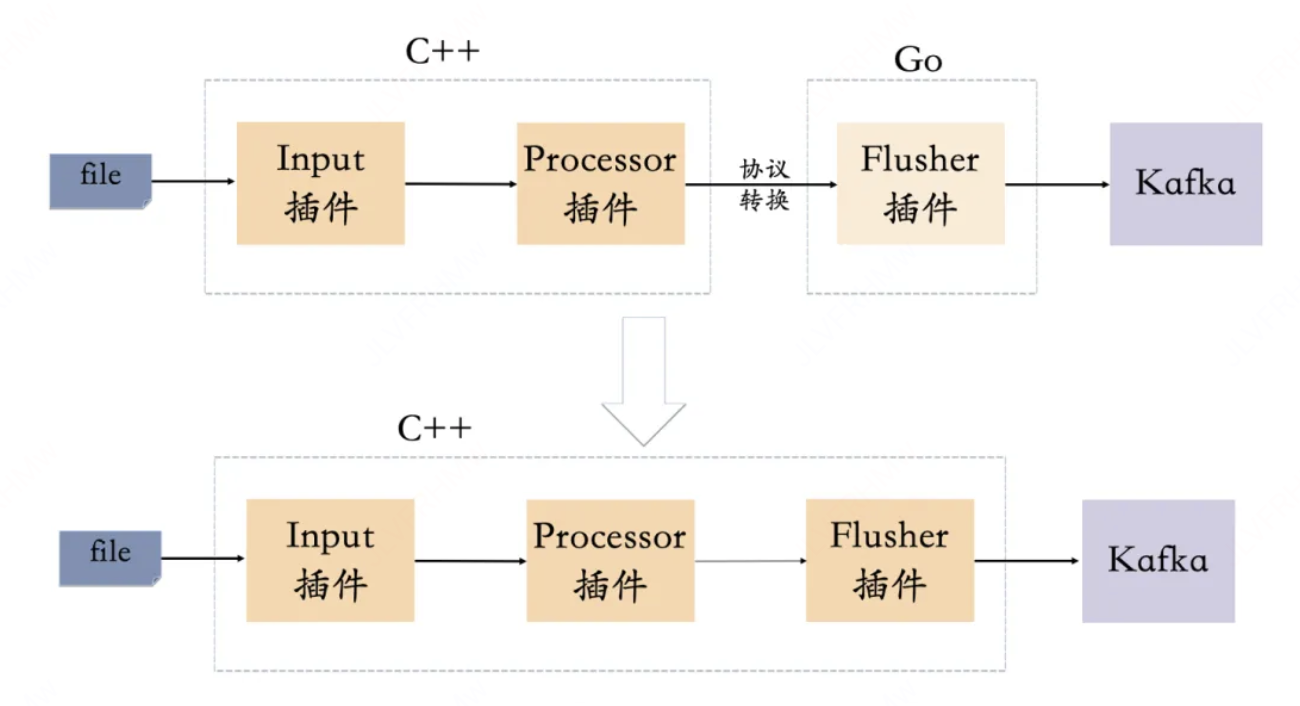
为了彻底解决这个问题,使用C++重写FlusherKafka插件,这样从采集一直到发送都是纯C++编写,这样不仅解决了垃圾回收带来的性能消耗,同时避免了C++调Go时协议转换(C++日志对象需要序列化成字节后,由Go在反序列化成对象)带来的CPU消耗和内存消耗(Go有自己独立的内存空间)。
通过此优化后,性能得到了巨大的提升,也是支撑下面测试结果的关键。
引入支持向量化的JSON库
在解决了垃圾回收的问题后,还有一块对性能影响比较大的是Json的序列化,在将日志数据发送到Kafka之前还需要将内存中的日志对象序列化成Json格式的字符串。
为了继续压榨性能,这里引入了字节开源的高性能C++ JSON库sonic-cpp。在Json在序列化中最消耗性能的地方就时处理转义字符,这里通过向量化来加速查找转义字符(原理和上面查找换行符一致),可以显著的提高处理速度。除此之外,它还有另一个优化,支持构建Json对象的时候传递 std::string_view ,这样可以避免大量内存拷贝的开销。
到这里iLogTail的性能已经拉满了。
发送Kafka失败支持回滚offset及退避重试
在原生的FlusherKafka插件中,如果发送Kafka失败数据是会丢失的。为了解决数据丢失的问题,实现了回滚offset的功能,对于每批要发送到Kafka的数据,都保存了这批数据最小的offset,当发送失败时,会在回调函数中回滚offset,读取文件的时候将从失败的位置重新读取。
如果某个任务一直发送不成功,为此还实现了类似TCP的拥塞控制,当发送Kafka失败的时候,会迅速降低采集端速度,当发送成功后则采集速度以指数上升,通过这个机制可以有效的避免存在问题的任务浪费线程资源。
收益
iLogTail开源版本与内部优化版本性能对比
总共创建150个采集任务,测试采集文件的日志数据发送到Kafka,限制CPU上限10C,内存上限为8G, GC堆为5G。同时加载运行这150个采集任务,观察CPU资源使用的情况。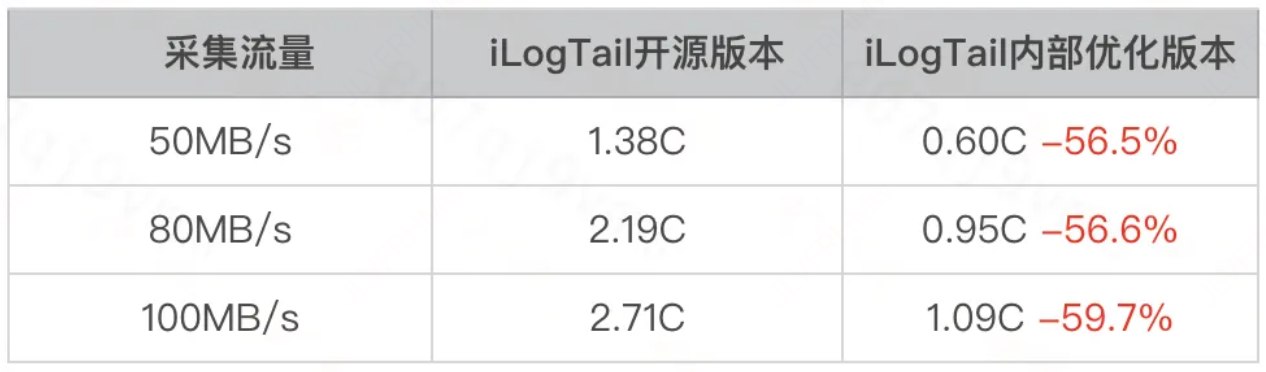
在小流量场景下,iLogTail内部版本相比于开源版本能节省56%的CPU,继续增加流量开源版本由于GC严重性能下降。
iLogTail内部版本大流量测试
如下的测试是在AMD机器上测试的,机器配置:384核 1.5T内存,总共600个采集任务,限制CPU上限20C,内存上限20G,iLogTail加载运行这600个采集任务,观察资源使用及采集延迟的情况。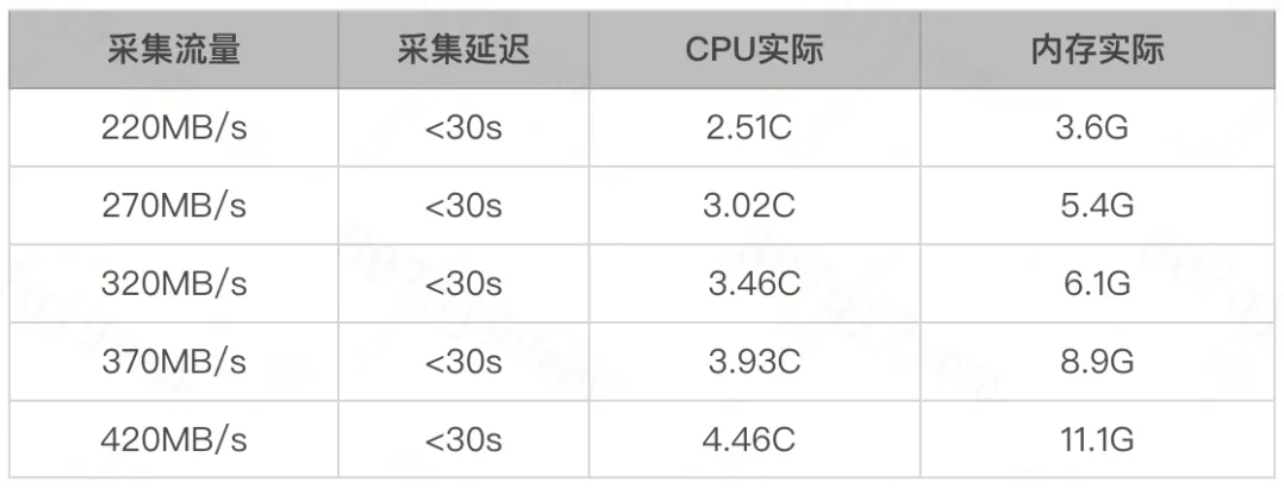
iLogTail在面临多任务超大流量时,能保证采集不延迟,且使用不到5core就能采集420+MB/s的流量,已经能满足内部的需求。
总结
经过多维度性能测试与优化迭代,iLogTail内部版本在资源效率、稳定性及扩展能力方面均实现显著突破,具体表现如下:
- 1、性能跨越式提升:在相同Kafka发送链路场景下,内部版本CPU资源消耗较开源版本降低56%,整体采集性能提升超过2倍。开源版本在流量增长时因频繁GC导致性能骤降,而内部版本通过内存管理与优化,实现高吞吐场景下的稳定运行。
- 2、超大规模流量承载能力:在384核服务器环境下,内部版本仅需分配5个CPU核心即可完成420+MB/s的日志采集吞吐,且保持零延迟。单节点可同时支撑600个采集任务的并行处理,内存资源控制在12G以内,充分验证其弹性扩展能力。
- 3、生产级可靠性保障:通过精细化资源隔离策略与自适应流量调控机制,内部版本成功突破在资源争抢、任务堆积等方面的瓶颈,满足企业级场景下对稳定性与资源效率的双重要求。
本次优化不仅验证了iLogTail的先进性,更使其成为支撑海量日志采集场景的核心基础设施,为后续千万级数据管道的构建提供了关键能力保障。