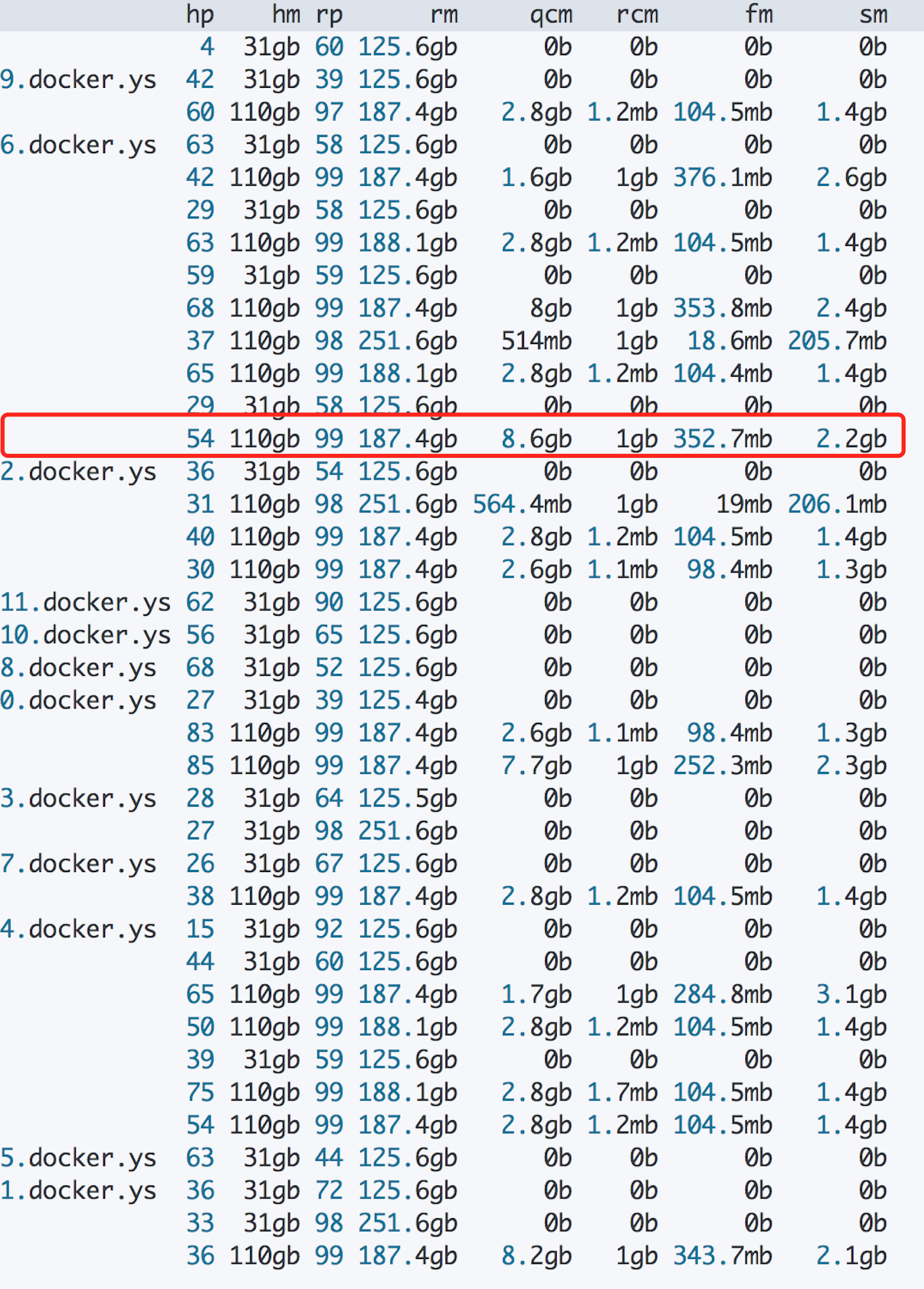
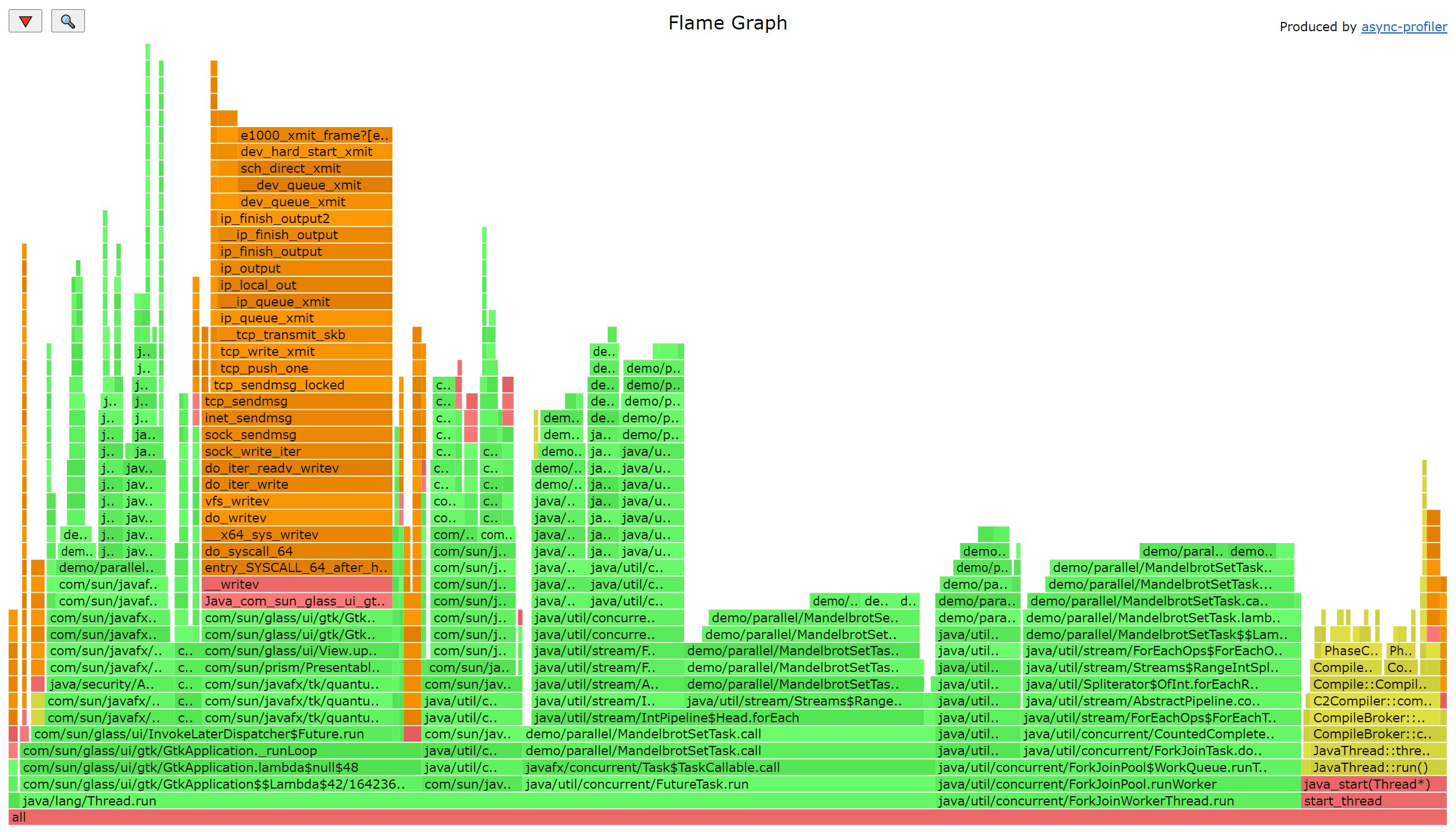
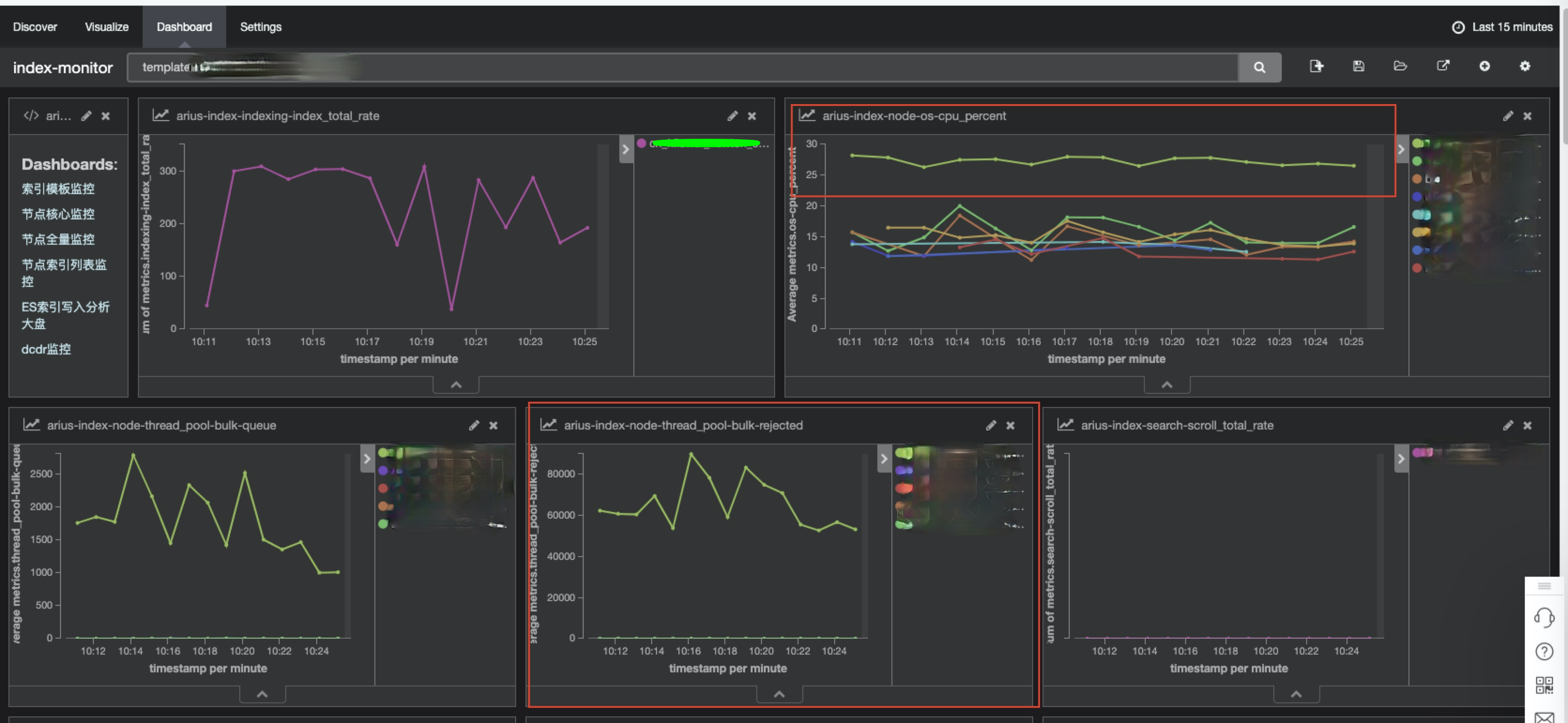
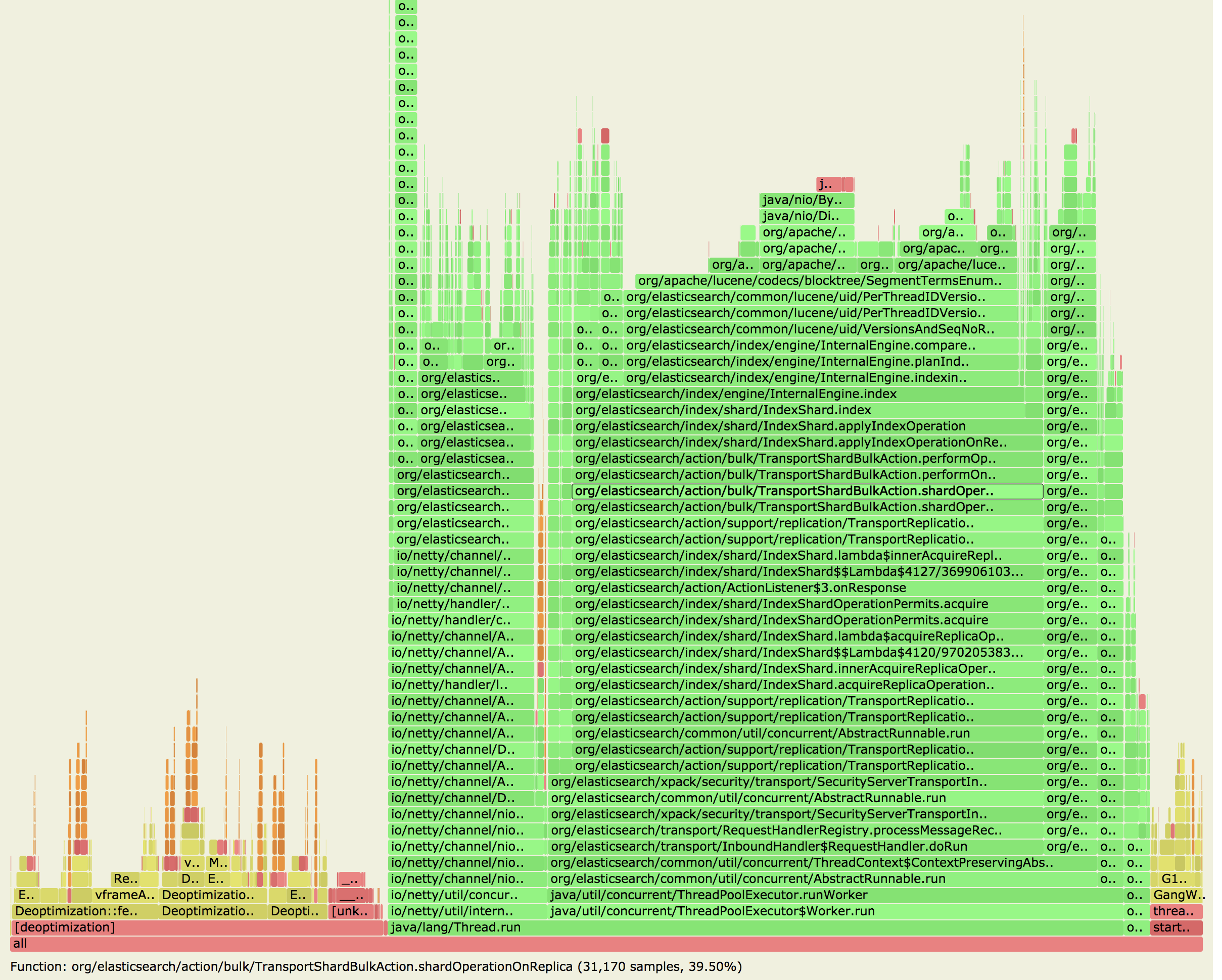
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
2020-12-21T20:50:15.009+0800: 4753827.928: [GC pause (GCLocker Initiated GC) (young) (initial-mark), 0.5723063 secs]
[Parallel Time: 66.9 ms, GC Workers: 33]
[GC Worker Start (ms): Min: 4753827940.4, Avg: 4753827940.5, Max: 4753827940.7, Diff: 0.4]
[Ext Root Scanning (ms): Min: 26.2, Avg: 27.3, Max: 54.9, Diff: 28.7, Sum: 899.6]
[Update RS (ms): Min: 0.0, Avg: 9.2, Max: 9.8, Diff: 9.8, Sum: 304.3]
[Processed Buffers: Min: 0, Avg: 19.9, Max: 35, Diff: 35, Sum: 657]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 0.5, Avg: 11.2, Max: 13.8, Diff: 13.3, Sum: 369.9]
[Termination (ms): Min: 0.0, Avg: 7.8, Max: 8.4, Diff: 8.4, Sum: 256.8]
[Termination Attempts: Min: 1, Avg: 1.5, Max: 4, Diff: 3, Sum: 51]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.5]
[GC Worker Total (ms): Min: 55.3, Avg: 55.5, Max: 55.7, Diff: 0.5, Sum: 1831.3]
[GC Worker End (ms): Min: 4753827996.0, Avg: 4753827996.0, Max: 4753827996.1, Diff: 0.1]
[Code Root Fixup: 0.4 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.6 ms]
[Other: 504.4 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 501.3 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.5 ms]
[Humongous Register: 0.2 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.2 ms]
[Eden: 320.0M(3264.0M)->0.0B(3392.0M) Survivors: 416.0M->288.0M Heap: 9068.7M(72.0G)->8759.2M(72.0G)]
[Times: user=1.70 sys=0.39, real=0.57 secs]
|