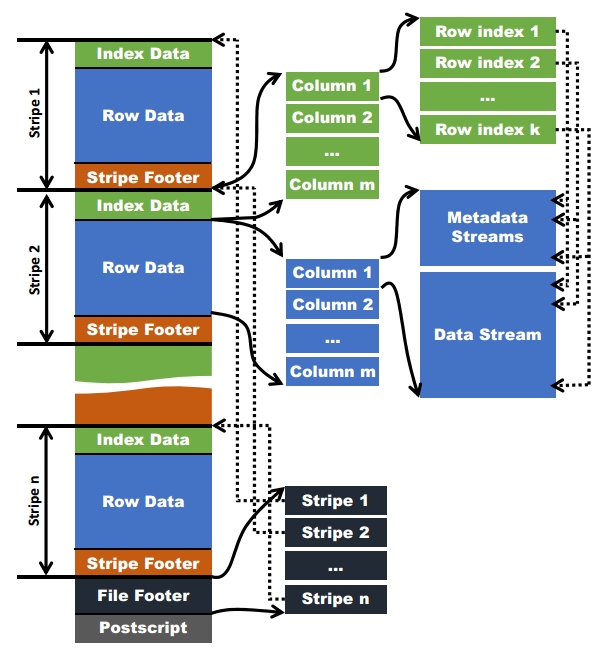
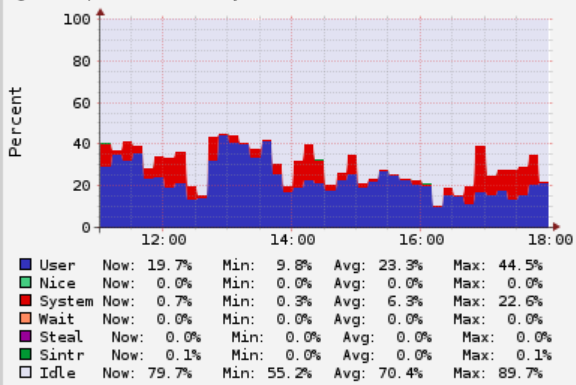
背景
最近Presto集群又上线了几个新业务,伴之而来的是OOM很频繁,且发生时间多在早晨8点左右,线上稳定性是高优需要解决的,所以查找了下导致Presto集群OOM的原因,发现了一些问题,这里抛砖引玉下,可能其他使用Presto的用户也会遇到类似的问题。
排查过程
我给一些业务划分了不同的label,这里说明下我们把Presto引擎改进了下,可以动态将机器划分不同的label,这样SQL查询时候指定不同的label,SQL调度时只根据指定的label查找机器即可。之后发现一个业务方的SQL会导致集群OOM。具体表现为,多次Full GC,之后OOM,看GC日志第一感觉应该是有内存泄露。
我通过审计日志(之前通过event-listener实现了个日志审计模块)拿到OOM时2K左右条SQL,发现SQL都是简单的SQL,类似这种:
1 | SELECT * FROM table WHERE year='2020' AND month='06' AND day='01' LIMIT 10; |
根据SQL,我猜测可能以下2种原因导致了OOM:
- 查询的表存在Hive视图(我让Presto支持了Hive视图)
- 异常SQL触发了内存泄露