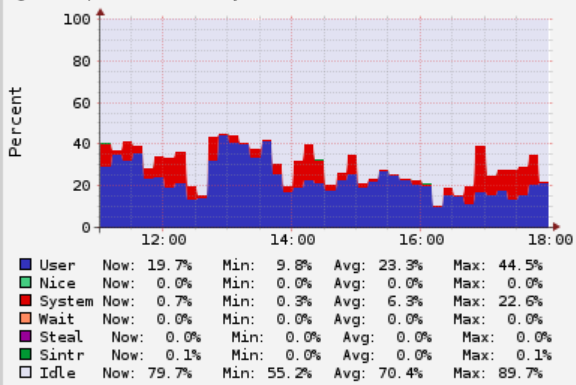
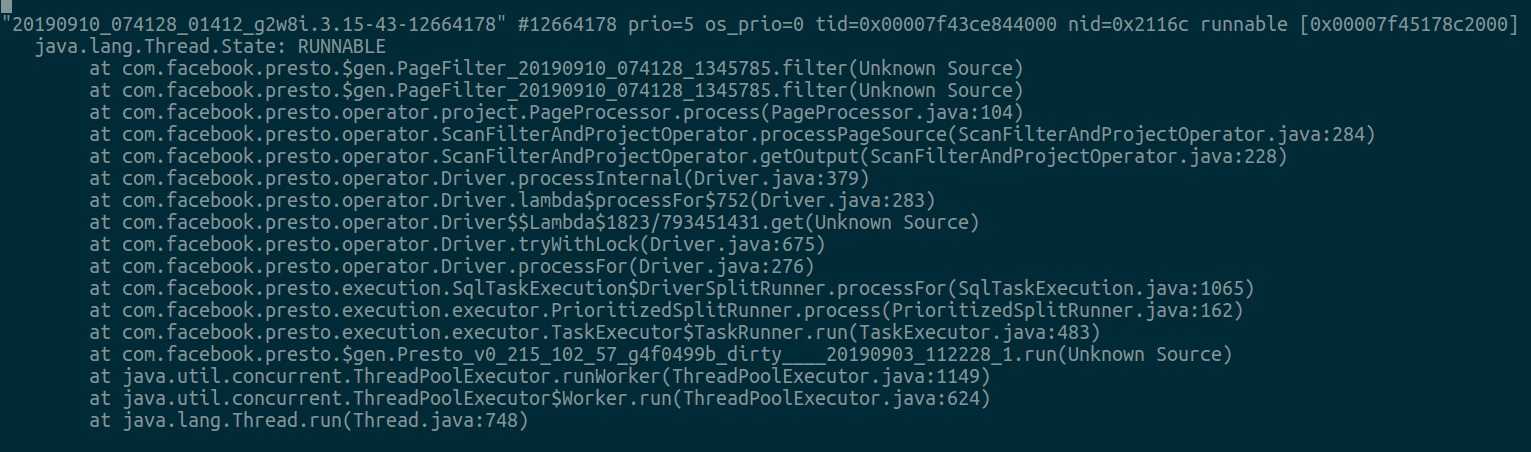
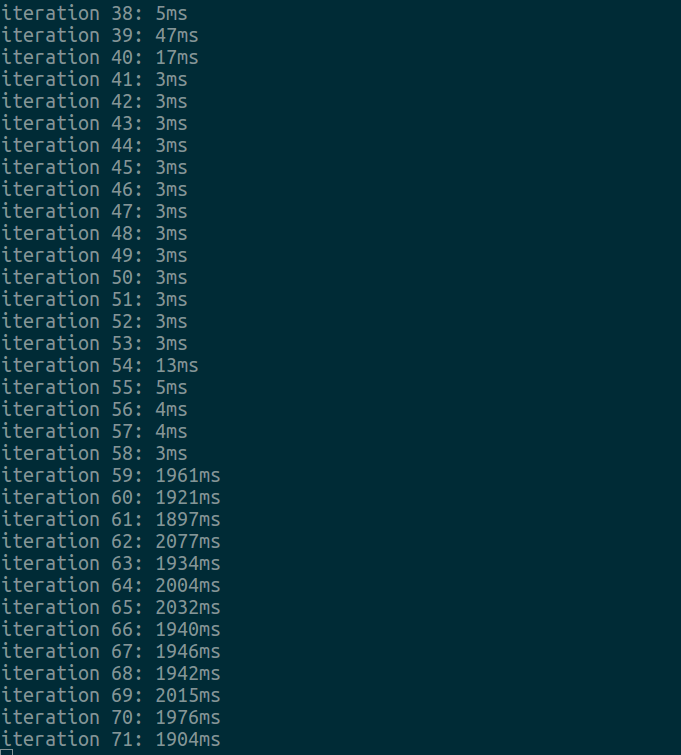
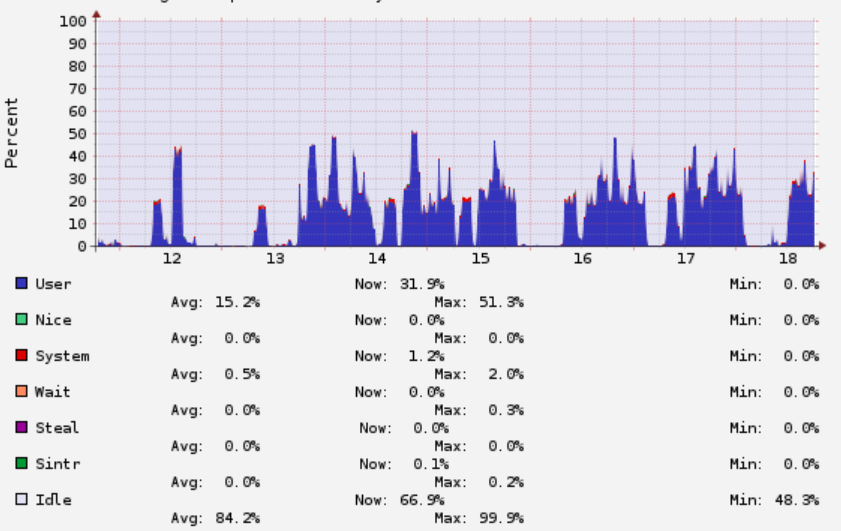
bool Compile::too_many_recompiles(ciMethod* method, int bci, Deoptimization::DeoptReason reason) { // Pick a cutoff point well within PerBytecodeRecompilationCutoff. uint bc_cutoff = (uint) PerBytecodeRecompilationCutoff / 8; uint m_cutoff = (uint) PerMethodRecompilationCutoff / 2 + 1; // not zero Deoptimization::DeoptReason per_bc_reason = Deoptimization::reason_recorded_per_bytecode_if_any(reason); if ((per_bc_reason == Deoptimization::Reason_none || md->has_trap_at(bci, reason) != 0) // The trap frequency measure we care about is the recompile count: && md->trap_recompiled_at(bci) && md->overflow_recompile_count() >= bc_cutoff) { // Do not emit a trap here if it has already caused recompilations. // Also, if there are multiple reasons, or if there is no per-BCI record, // assume the worst. if (log()) log()->elem("observe trap='%s recompiled' count='%d' recompiles2='%d'", Deoptimization::trap_reason_name(reason), md->trap_count(reason), md->overflow_recompile_count()); returntrue; } elseif (trap_count(reason) != 0 && decompile_count() >= m_cutoff) { // Too many recompiles globally, and we have seen this sort of trap. // Use cumulative decompile_count, not just md->decompile_count. if (log()) log()->elem("observe trap='%s' count='%d' mcount='%d' decompiles='%d' mdecompiles='%d'", Deoptimization::trap_reason_name(reason), md->trap_count(reason), trap_count(reason), md->decompile_count(), decompile_count()); returntrue; } else { // The coast is clear. returnfalse; } }
void GraphKit::uncommon_trap(int trap_request, ciKlass* klass, constchar* comment, bool must_throw, bool keep_exact_action) { Deoptimization::DeoptReason reason = Deoptimization::trap_request_reason(trap_request); Deoptimization::DeoptAction action = Deoptimization::trap_request_action(trap_request); switch (action) { case Deoptimization::Action_maybe_recompile: case Deoptimization::Action_reinterpret: // Temporary fix for 6529811 to allow virtual calls to be sure they // get the chance to go from mono->bi->mega if (!keep_exact_action && Deoptimization::trap_request_index(trap_request) < 0 && too_many_recompiles(reason)) { // This BCI is causing too many recompilations. action = Deoptimization::Action_none; trap_request = Deoptimization::make_trap_request(reason, action); } else { C->set_trap_can_recompile(true); } break; case Deoptimization::Action_make_not_entrant: C->set_trap_can_recompile(true); break;