Redis全名叫做Remote Dictionary Server,从全称就可以看出dict是Redis里重要的数据结构,看了下dict.c里的源码,简单分析下。
dict.c主要是实现了哈希功能,实际上实现哈希(字典)常见的方法有几种:
<1>比如我们数据结构课上学的数组和链表法,但是这种方法适用于元素个数不多的情况下
<2>使用复杂的平衡树(B-等等),性能比较不错,比如MySQL里的索引就使用了这种方法
<3>哈希表,兼顾了高效和简单性,Redis选择了这种方法。
我们就解读下dict.c里源码里的数据结构吧,我们知道hash表的性能由hash表的大小和解决冲突的方法决定。Redis里使用了两个哈希表(ht[0])和哈希表(ht[1]),hash[0]是字典主要使用的hash表,而hash[1]主要对0号哈希表进行rehash时才使用。读者可能不明白这个地方啥意思?其实就是,程序每次申请几个字节(默认为4字节),当key/value数量达到规定时,程序申请的4字节就翻一倍(这里使用了慢迁移),那什么时候rehash呢?我们知道size == used(根据下面的dictht结构体)时,达到最理想状态,所以当used/size > 1时,就进行rehash。我们先看看dict.h里定义的几个结构体吧:
dict:
1 | typedef struct dict { |
dictType:
1 | //每种hash table的类型,里面既有成员函数,又有成员变量,模拟的C++类,每个函数带有的privdata均为预留参数 |
dictht:
1 | /* This is our hash table structure. Every dictionary has two of this as we |
dictEntry:
1 | //hash表中每一项key/value,若key的映射值,以单链表的形式保存 |
dict.h一共有这四种结构,每个结构体里的每个变量的用途,我都已经注释出来。
根据程序分析出整个字典结构如图所示(此时的状态为dictadd,且未出现rehash和rehash也未在进行中):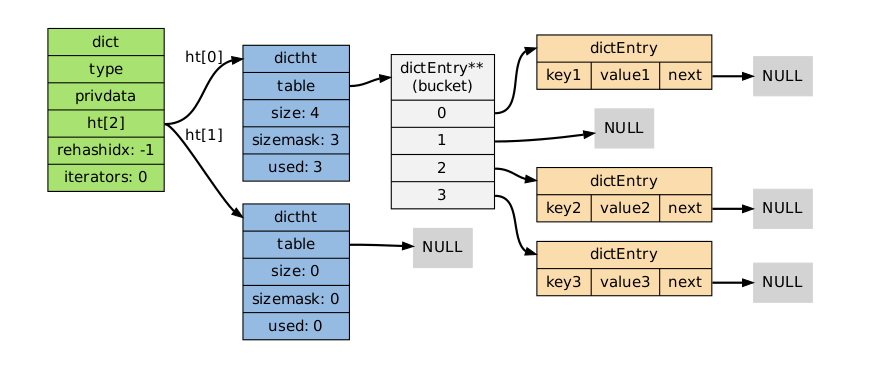
我们之后再说下程序的执行流程吧:
首先是dict初始化,init_hash_dict –> dictCreate –> _dictInit –> _dictRest
上面流程代码都很简单,就是把dict结构体和dictht里面的数据都初始化。
然后是添加键值到字典,这个地方比较难懂,也是重点,因为它包括的操作比较多,分为三种情况:
<1>如果字典为未初始化(也即字典的0号哈希表的table属性为空),那么程序需要对0号哈希表进行初始化。
<2>如果在插入时发生了键碰撞,处理碰撞,链表法
<3>如果插入新元素使得字典满足了rehash条件,那么启动相应的rehash程序(used / size > 1)。
这里有个需要注意的地方,如果rehash正在进行中(ht[0]数据–>ht[1]),那么选择ht[1]作为新键值对的添加目标,否则ht[0]作为新键值对的添加目标。
本来想长篇大论呢,但是学校网速真的是太卡了,不写了,看看其他的吧。
参考资料: