一致性hash算法在分布式系统里面使用比较广,我也只是听说过这个概念,今天看到一个一致性hash开源库,随手写篇文章,记录下吧。
假如我们使用普通的哈希方式来处理负载均衡,到目标机器的映射使用的算法为:
hash(o) mod n (n表示机器的总数)
如果需要增加或减少一台机器的时候,算法就变为 hash(o) mod (n + 1) / hash(o) mod (n - 1)
不仅需要重新编写代码,当服务器做了大量变更,大量的o会重定向不同的服务器而导致了缓冲不被命中,所以此时,就提出了一致性hash算法。
一致性哈希算法
简单的说,哈希函数将o映射到 0 ~ 2^32 - 1的值区间,将这些数字头尾相连,然后将它们组织成一个闭合的圆环。如图一所示: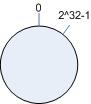
要实现一致性哈希算法,思路就是下面2个步骤:
将数据通过一定的hash算法映射到环上
hash(object1) = key1;
…
…
hash(object4) = key4;
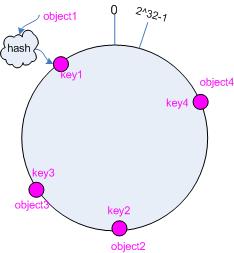
将机器通过哈希算法映射到环上
假如有三台cache机器,A,B,C,一般情况下hash计算是采用机器的IP或者机器唯一的别名作为输入值。
hash(cache A) = key A;
…
…
hash(cache B) = key C;
然后顺时针方向计算,将所有object(数据)存储到离自己最近的机器上。
如上图所示:object1将存储到 cache A,object2和object3将会存储到 cache C,object4将会存储到 cache B。
添加或删除机器
假如B 机器被移走或者坏掉了,根据顺时针存储到最近的机器的特性,之前存储到B机器的objects(数据)将会转到C机器(因为顺时针离C最近),如下所示: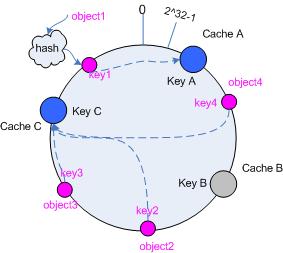
同样添加了新机器也是同理。
虚拟节点
一致性哈希算法在服务节点太少或不均匀时,容易造成数据倾斜问题,导致平衡性问题。hash算法不能保证平衡的,在一致性哈希算法中,为了尽可能的满足平衡性,引入了虚拟节点。
虚拟节点是实际节点(机器)在hash空间的复制品,一个实际节点对应了若干了虚拟节点,当我们增加一个机器时,我们在环里增加几个其虚拟节点,当我们移掉它时,我们把其虚拟节点从环中一块移除掉。实际上就是对一个机器节点计算多次哈希,每个计算结果位置都放置一个此服务节点,成为虚拟节点,具体做法可以在机器IP或主机名的后面添加编号来实现,如Node1-1,Node1-2。
例如,有两台机器A和C,引入了虚拟节点后,就会有4个节点,分布更均匀,如下图所示所示: