简单说下,2011年左右的Paper,Paper里说Twitter的实时索引和检索系统叫做Earlybird,Paper中主要讲了2件事,第一个就是支持Twitter的实时索引的倒排索引结构是怎么样的,第二个就是利用Java并发模型,处理并发读写。
该引擎功能
- 低延时、高吞吐能力;
- 能处理突发峰值(Weibo的特性);
- 突出时效性,时间越近,排名应该越靠前;
- 该实时引擎支持AND、OR、NOT以及短语查询,实时性大约10S,查询latency 50ms;
该实时引擎,基于Lucene,使用Java开发,理由是
- 利用已存在的Lucene代码,并用来做全量索引;
- 适用于Twitter以JVM为中心的开发环境;
- 利用Java和JVM提供容易理解的并发模型;
其实上面几条理由与阿里很多开发项目类似,但是阿里的搜索引擎是C++编写的,质量也是非常不错的,叫问天(HA3)。
索引构建过程
Earlybird处理三种信号:
- 静态信号,初次建立索引时被添加;
- 共鸣信号,动态更新的,比如tweet转发次数;
- 搜索用户信息,用来个性化排序;
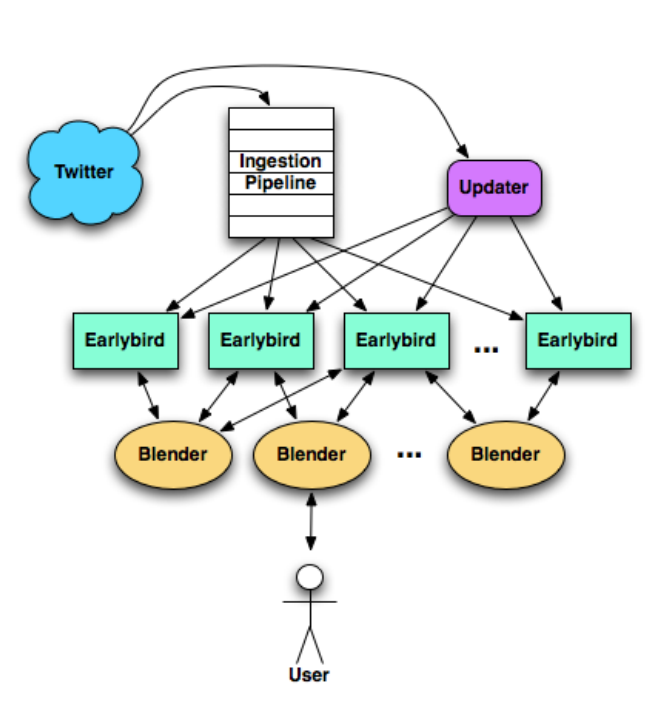
- 用户发布tweet,之后被发送到一个队列,叫做Ingestion Pipeline里。这些tweet会被分词,并被加上一些meta信息,比如语言等;
- 为了处理大容量,tweet按照哈希算法,分发到各个Earlybird服务上,之后将tweet实时地建立索引;
- 如上图所示,有一个Updater服务,它推送共鸣信号到Earlybird服务,用于动态地更新索引,比如tweet转发信息等。
查询过程如下
- 当查询请求过来,先到达前端“Blender”,Blender解析请求,并将搜索用户的本地社交图谱信息也下发到Earlybird服务;
- Earlybird服务执行相关性计算并排序,并将排序好的tweet(排序分数高的,最近发生的tweets)返回给Blender;
- Blender合并各个Earlybird返回的列表,并重排序后返回给用户;
Term字典
Twitter实时索引现在不支持一些高级查询,比如通配符。所以term词典使用hash表实现。没有选择Java默认的HashMap,因为其不是GC友好的,Earlybird实现了个开链法的哈希表(个人猜测是不是与Redis的渐进式哈希相似呢?)每个Term被分配了一个唯一且单调递增的id作为key,value包含以下两部分信息:
- Term对应的倒排索引数据长度;
- 指向倒排索引数据末尾的指针;
动态(active)索引
Paper里首先介绍了现在存在的索引组织方式不适合实时索引,如将新发生的tweet放到postings链最后面,但是读取时候需要倒序读取,这个是不支持现在流行的压缩算法的,而如果将新的数据放到倒排索引前面,这带来的问题就是内存分配的问题。Earlybird使用了一个更简单的方式,分离索引读和写的方式。
每个实例维护了多个索引分段(目前是12个instance),每个分段保存相对较少量的tweet(目前是2^23~840万 tweets)。新增加的tweets被分到同一个segment(分段)中,满了之后再放下一个,这样,在任何时候只有一个分段被更改,其他都是只读状态,当一个segment满了,停止接收新的tweets时,会做只读优化。
postings列表在优化之前直接使用整数数组,按照docid升序存储,并且不做压缩,因此查找可以直接二分查找。postings增长时分配空间以pool为单位,分配空间按指数预留空间,分为4个,大小分别为应2^1、2^4、2^7、2^11 。如果一个pool满了,另一个pool将会分配。每个pool里面有若干个slice,每个slice保存一个term的postings列表,每个postings列表里面存储着一个term的postings信息,每个postings是一个32-bit的整数,24-bit用作文档id;8-bit用作位置id,保存term在tweet中出现的位置。因为tweet有140字符限制,所以8-bit足够用。在建立索引时,先尝试填满2^1pool中的slice,如果填满,就转到2^4的pool的slice,以此类推。term 字典中保存term对应的最后一个pool的中postings list尾部指针。如下图所示: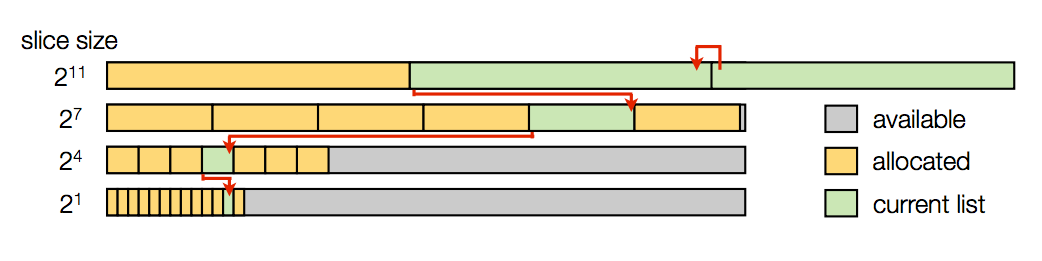
索引优化
一旦动态索引停止接收新的tweets时,即此segment的tweets超过840W时,后台执行只读索引优化。优化过程中,根据老的索引数据,新的索引数据会被创建,原始索引数据不做变化,一旦完成构建,原始索引数据将被新的索引替换。postings链分为两种,长的和短的,以长度1000为界限。短的,即postings链长度小于1000,postings保持原样(24-bit文档id加上8-bit的位置信息),但是postings会按照时间逆序排列。对于长的postings链,采用了基于block的压缩算法,PForDelta和Simple9。
并发管理
对于实时索引来说,一个重要的需求就是在多线程环境下处理好并发读和写操作。当然这个只用于动态索引当中,静态索引(优化后的)只有读操作。因为不懂Java,这块简单说下吧,Paper里说Java和JVM提供了一个非常容易理解的并发内存模型。11个只读段并发读不需要锁,唯一的可读可写段使用volatile关键字实现高效同步,然后也使用了 jvm memory barrier。懂Java得同学,通过以下新tweet添加处理过程,可能就明白一二了。
tweet里的每个term,首先去查询对应的词典入口,在字典中,term被映射到term id。它包括2个信息,Term对应的倒排索引数据长度和指向倒排索引数据末尾的指针。通过末尾的指针,信息被添加到新的postings链中。如果没有足够的空间插入新的postings信息,新的slice被分配。如果term是第一次遇到,它被添加到词典并且分配下一个term id。postings被添加到slice时,term并发的增加计数,指向postings链尾巴的指针也被并发更新。当tweet里的所有term都被处理后,增加maxDoc变量,此变量表示目前遇到的最大文档id。
简单就写这么多吧,没看明白的同学可以自己仔细阅读下twitter的这篇实时索引Paper吧,地址:
http://www.umiacs.umd.edu/~jimmylin/publications/Busch_etal_ICDE2012.pdf