随着索引数据的增大以及请求的增多,分布式搜索是最好的一种解决方案,主要解决两个问题,其一是能让单台机器load所有索引数据到内存中,其二是请求延时大,解决请求latency问题。我之前为团队写了篇专利,内容是关于分布式搜索解决方案的,所以粗略的看了下大部分开源的搜索引擎是怎么实现分布式的,后面的文章我会简单说下常见的搜索引擎的分布式解决方案。
首先我们先说下几个简单概念,分布式搜索都是M*N(横向切分数据,纵向切分流量)这个维度去解决问题的,虽然不同产品或场景概念不完全相同,读者可以简单认为一份完整的数据,被均分为M份,每一份被称为一个分配(Shard或者Partition),然后提供对每个Shard提供N份副本(Replica)。那么分布式的设计就围绕着以下问题:
- 如何选择合适的分片(Shard),副本(Replica)的数量
- 如何做路由,即怎么在所有Shard里找到一份完整的数据(找到对应的机器列表)
- 如何做负载均衡
- 如果提高服务的可扩展性
- 如何提高服务的服务能力(QPS),当索引和搜索并发量增大时,如何平滑解决
- 如何更新索引,全量和增量索引的更新解决方法
- 如果提高服务的稳定性,单台服务挂掉怎么不影响整体服务等等
下面就说下常见的搜索引擎的分布式解决方案,因为开源的搜索产品基本上都没有在工作中用过,对代码细节并不是太了解,只是研究了下其原理,所以理解的会有些偏差,看官们如果发现错误直接指出即可。
Sphinx/Coreseek
Sphinx的流程还是很简单的,可以看下其流程图: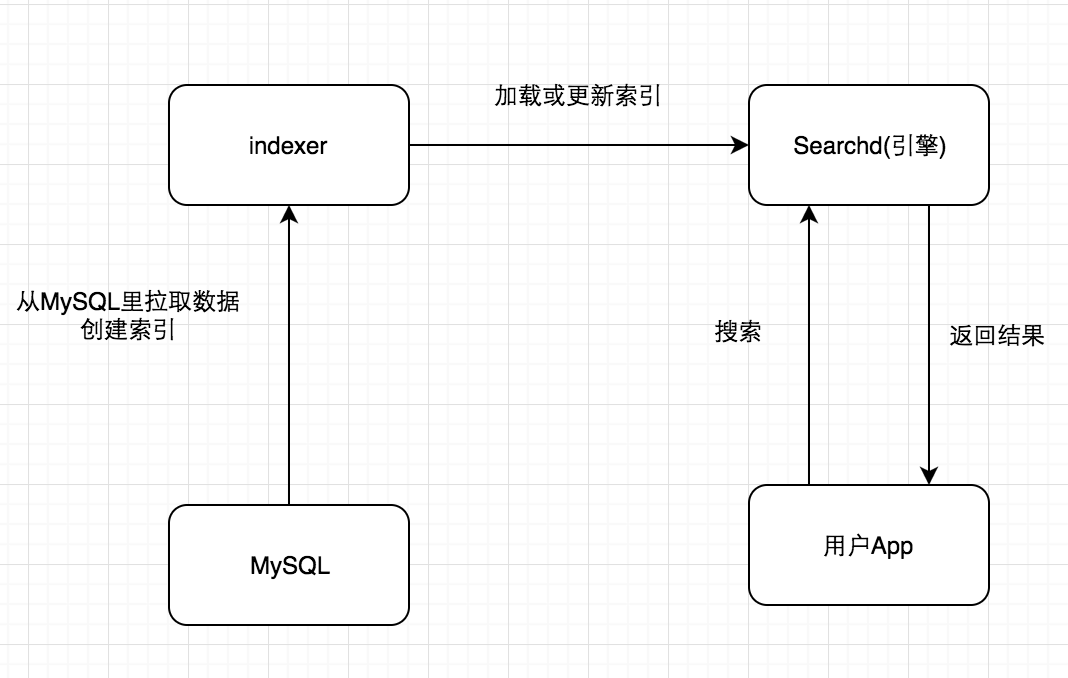
需要支持分布式的话,需要改下配置,大致是这样子的:
1 | index dist |
从图中也可以看出,需要在配置列表里配置好其他shard的地址。查询过程为:
- 连接到远程代理
- 执行查询
- 对本地索引进行查询
- 接收来自远程代理的搜索结果
- 将所有结果合并,删除重复项
- 将合并后的结果返回给客户端
索引数据复制同步的方法也是常用的两种:
- 主从同步
- 增量更新索引
方法也是设置crontab,添加2个选项,一个是重建主索引,一个是增量索引更新。
当然为了避免单点以及增加服务能力,肯定有多个Replica,解决方法应该也是配置或者haproxy相关的方法解决,从上面可以看出,Sphinx很难用,自动化能力太弱,所以很多大厂要么不再使用Sphinx要么基于其二次开发。
Solr
Solr提供了两种方案来应对访问压力,其一是Replication,另一个是SolrCloud。我们此处只说Replication原理。
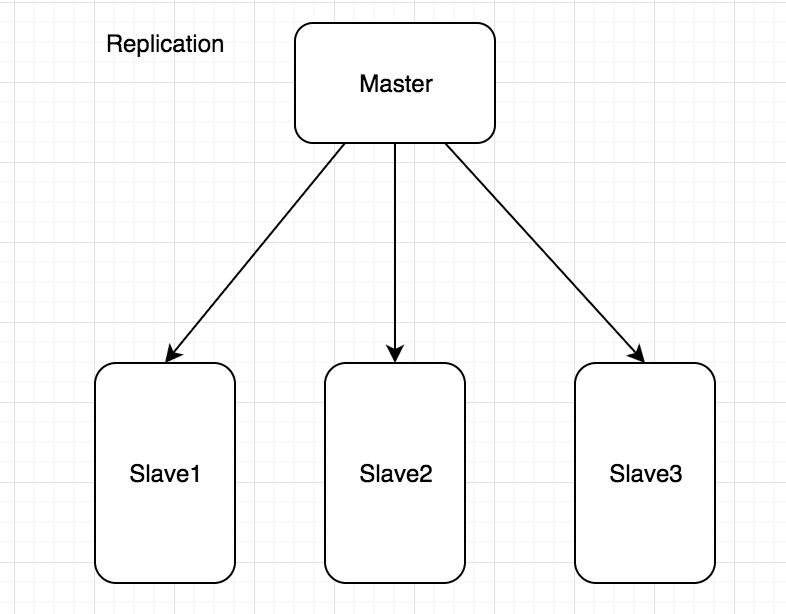
Replication采用了Master/Slave模式,也就是说由一个主索引和多个从索引构成,从索引从主索引复制索引,主索引负责更新索引,从索引负责同步索引和查询。本质上是读写分离的思想,MySQL/Redis等数据库也多是这种方式部署的。有两种部署方式:
第一种
第二种
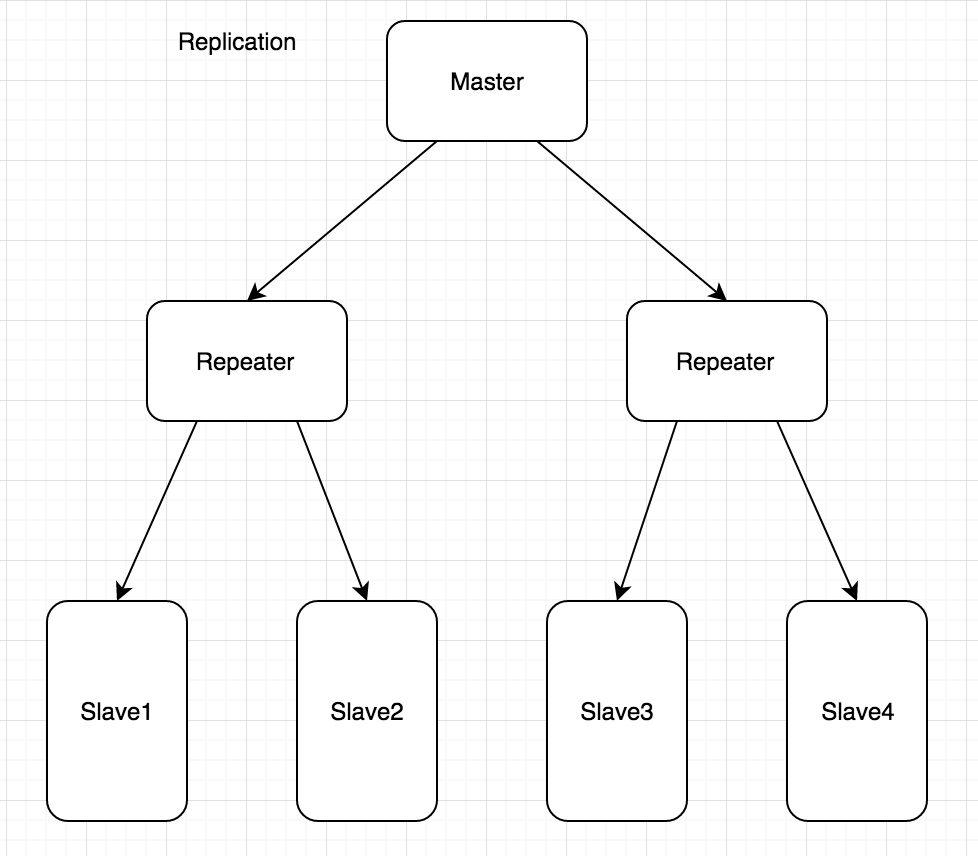
与第一种相比多了一层Repeater,Repeater既扮演了Master角色,又扮演了Slave功能,主要解决单个Master下Slave太多,Master压力太大的问题。
Master与Slave之间的通信是无状态的http连接,Slave端发送不同的Command从Master端获得数据。原理就是Master那边有个标志位和版本号,用于获取正确的数据版本,然后数据扔到Slave临时目录下,数据完整后,再覆盖原有数据。多个副本的方法应该与Sphinx相似,一般也是通过通过上游负载均衡模块如Nginx,HaProxy来分流。
SolrCloud
因为Solr Replication不好用,本质上还不算真正分布式的,所以Solr从4.0开始支持SolrCloud模式。特性不少,主要说两个吧:
- 配置文件统一管理,扔到Zookeeper上
- 自动做负载均衡和故障恢复,不再需要Nginx或HaProxy的支持
逻辑图
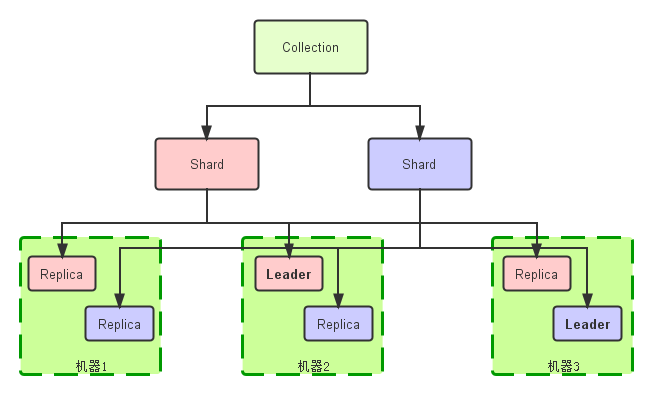 - Collection:逻辑意义上一份完整的索引
- Shard:上文已说,就是索引的1/N分片
- Replica:Shard的一个拷贝
- Collection:逻辑意义上一份完整的索引
- Shard:上文已说,就是索引的1/N分片
- Replica:Shard的一个拷贝
每个Shard,即相同的Replica下都会有一个leader,leader选举由Zookeeper完成。虽然有leader的概念,但是其实SolrCloud分布式是去中心化的,意思就是说,leader和非leader都能提供查询功能(也有修改和删除功能,搜索场景应用不多吧?),而更新索引,创建Collection/Shard/Replica(即扩容)只能由leader完成,避免产生并发修改问题,当非leader节点收到修改操作请求时,将信息存储在zookeeper中相应节点上,leader节点会一直对该节点进行watch,发现变化就实时做处理。
Zookeeper信息
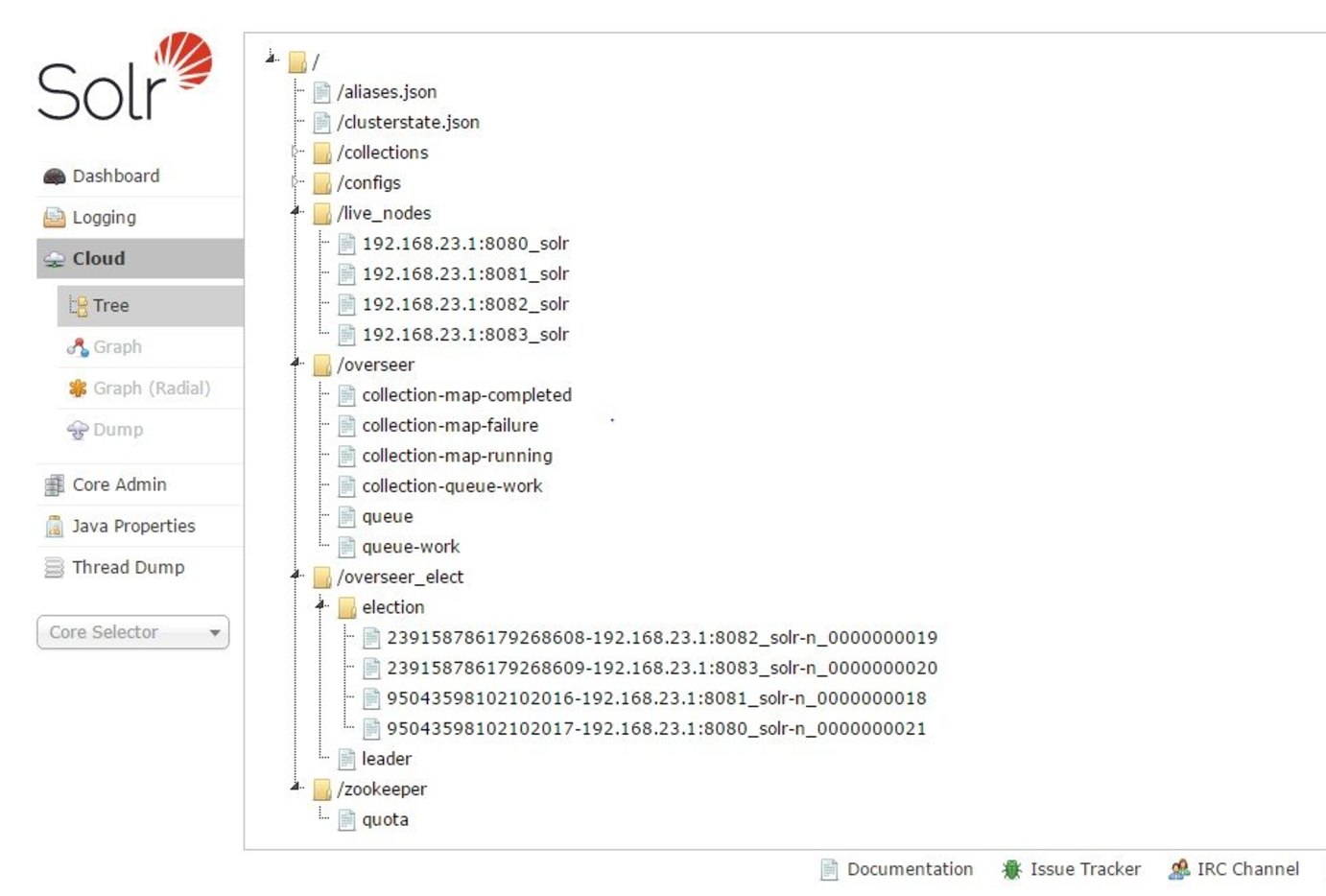
创建索引
- 任意节点收到创建索引请求后,转换成json格式存储到zk的/overseer/collection-queue-work的children节点上
- leader线程一直监控collection-queue-work节点,检查到变化后,取出json数据,根据信息计算出需要创建的shard、replica,将创建具体replica的请求转向各对应节点
- 各节点创建完具体的replica后,将该节点的状态(创建成功与否等)更新到/overseer/queue的children节点上
- leader线程监控/overseer/queue节点,将overseer/queue的children节点的状态更新至/clusterstate.json
- 各节点同步/clusterstate.json,整个集群状态得到更新,新索引创建成功
更新索引
- 根据路由规则计算出该doc所属shard,并找出该doc所属的shard对应的leader
- 如果当前Replica是对应Shard且是leader,首先更新本地索引,然后再将doc转向该Shard的其余Replica
扩容/缩容
- 停掉某台Solr,更新集群状态到/clusterstate.json
- 增加一台Solr,从leader出复制相同的数据,然后配置写到/clusterstate.json
查询
- 去中心的,leader和非leader一样功能,Replica接收搜索请求时,从Zookeeper中获取该Replica对应的Collection及所有的Shard和Replica
- 将请求发送到该Collection下对应的Shard,然后负载均衡到对应的Replica
SolrCloud也有其他功能,比如Optimization,就是一个运行在leader机器的进程,复杂压缩索引和归并Segment;近实时搜索等。总体看SolrCloud解决了Solr Replication遇到的一些问题,比Sphinx更好用,更自动化。
一号店
很多大一点的厂商如果不自研搜索引擎的话,并没有使用SolrCloud,而多基于Solr/Lucence。比如一号店的分布式搜索解决方案,如下所示:
http://www.infoq.com/cn/articles/yhd-11-11-distributed-search-engine-architecture
Broker就相当于Proxy,扮演了路由功能,很多厂商做的与一号店有相似之处。因为没有leader选举,所以索引的更新就由其他模块来做了。
ElasticSearch
ElasticSearch的倒排索引也是基于Lucence实现的。功能强大,不仅提供了实时搜索功能,还有分析功能,DB-Engines上面的搜索引擎排名,目前已经超越Solr排名第一位了。因为太强大了,功能也特别多,我研究还不够深,简单说下吧。
es会将集群名字相同的机器归为一个集群(业务),所以先说下启动过程。
启动过程
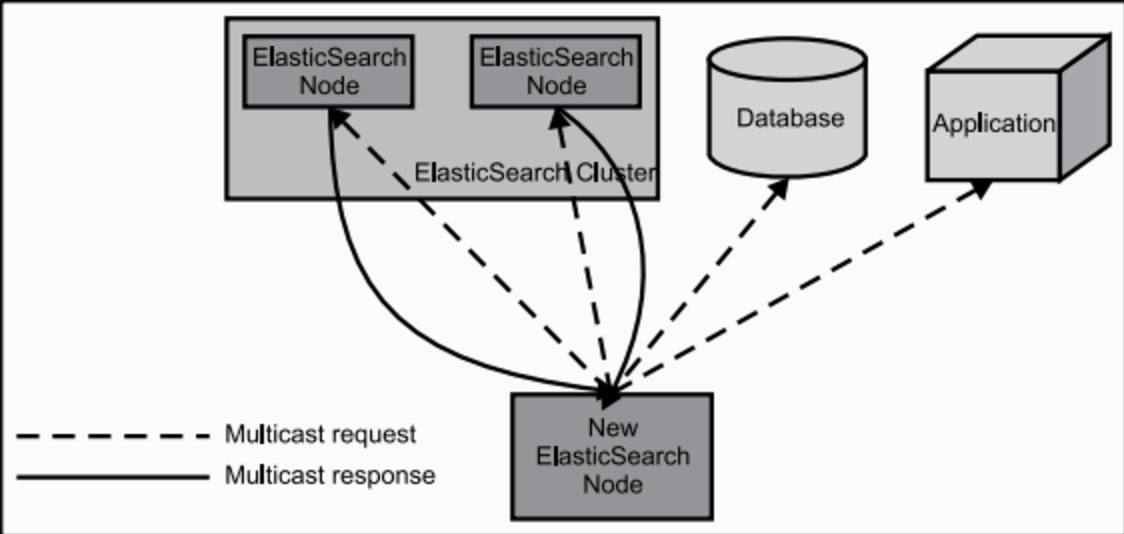
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。
leader选举
与SolrCloud相似,也是去中心化的,但是没有使用Zookeeper,而是自己实现了分布式锁,选主的流程叫做 ZenDiscovery(详情见第三个参考链接):
- 节点启动后先ping(这里的ping是 Elasticsearch 的一个RPC命令。如果 discovery.zen.ping.unicast.hosts 有设置,则ping设置中的host,否则尝试ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点)
- Ping的response会包含该节点的基本信息以及该节点认为的master节点
- 选举开始,先从各节点认为的master中选,规则很简单,按照id的字典序排序,取第一个
- 如果各节点都没有认为的master,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举
- 最后选举结果是肯定能选举出一个master,如果只有一个local节点那就选出的是自己
- 如果当前节点是master,则开始等待节点数达到 minimum_master_nodes,然后提供服务
- 如果当前节点不是master,则尝试加入master
选举完leader后,主节点leader会去读取集群状态信息;因为主节点会监控其他节点,当其他节点出现故障时,会进行恢复工作。在这个阶段,主节点会去检查哪些分片可用,决定哪些分片作为主分片。
分片
es在创建索引时,自己设置好分片个数,默认5个,整个过程类似于分裂的概念,如下图所示:
至于读写、写操作等于SolrCloud相似,等我细研究后后续再说吧,也可以说下实时索引怎么做的,细节很多,下次再说吧。至于文中为什么不说Lucence,因为Lucence其实就是个index lib,只是解决倒排、正排索引怎么存放的,并不是一个完整的搜索引擎解决方案。而ES为什么能脱颖而出的主要原因是配套设施完善,工具,Web UI都是非常赞的,对于很多开源产品,它能后来居上的主要原因就是它真实的能解决用户遇到的问题或者比其他产品更好用。搜索引擎发展这么多年了,架构这块能做的基本上大家都差不太多,最后能脱颖而出的肯定是第三方工具做的更完善,更好用的了。
PS:
至于阿里搜索怎么做的,可以参考下这个文档,包括了阿里搜索里用到的很多基础模块了:
https://share.weiyun.com/f66e79d9f6897d0aac683361531cf00d
参考链接:
http://blog.haohtml.com/archives/13724
http://www.voidcn.com/blog/u011026968/article/p-4922079.html
http://jolestar.com/elasticsearch-architecture/