前言
我们实时引擎组新引入了一款分布式SQL查询引擎,名字叫Presto,目前已经调研和测试了2个月了,并且期间某平台也从impala平台迁入到了Presto平台,查询性能有了2-3倍的提升(各种原因导致),所以本文将结合作者这段时间的测试和调研研究,来揭开Presto的神秘面纱。
Presto是神马
Presto是由Facebook开发的一个分布式SQL查询引擎, 它被设计为用来专门进行高速、实时的数据分析。它的产生是为了解决Hive的MapReduce模型太慢以及不能通过BI或Dashboards直接展现HDFS数据等问题。Presto是一个纯粹的计算引擎,它不存储数据,其通过Connector获取第三方Storage服务的数据。
历史
- 2012年秋季,Facebook启动Presto项目
- 2013年冬季,Presto开源
- 2017年11月,11888 commits,203 releases,198 contributors
功能和优点
- Ad-hoc,期望查询时间秒级或几分钟
- 比Hive快10倍
- 支持多数据源,如Hive、Kafka、MySQL、MonogoDB、Redis、JMX等,也可自己实现Connector
- Client Protocol: HTTP+JSON, support various languages(Python, Ruby, PHP, Node.js Java)
- 支持JDBC/ODBC连接
- ANSI SQL,支持窗口函数,join,聚合,复杂查询等
架构
- Master-Slave架构
- 三个模块
- Coordinator、Discovery Service、Worker
- Connector
Presto沿用了通用的Master-Slave架构,Coordinator即Presto的Master,Worker即其Slave,Discovery Service就是用来保存Worker结点信息的,通过HTTP协议通信,而Connector用于获取第三方存储的Metadata及原始数据等。
Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行;Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。假如配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
部署方式
Presto常见的部署方式如下图所示: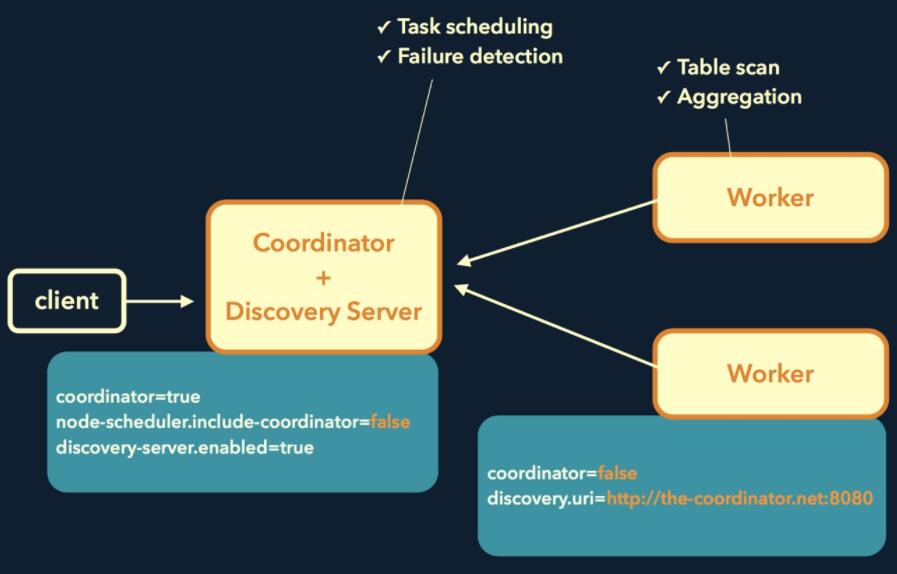
Coordinator与Discovery Server耦合在一起混合部署,然后部署多台Worker。然而这个有个问题,就是Coordinator存在单点问题,我们目前线上使用ip漂移的方法(网卡绑定多ip)。如下图所示: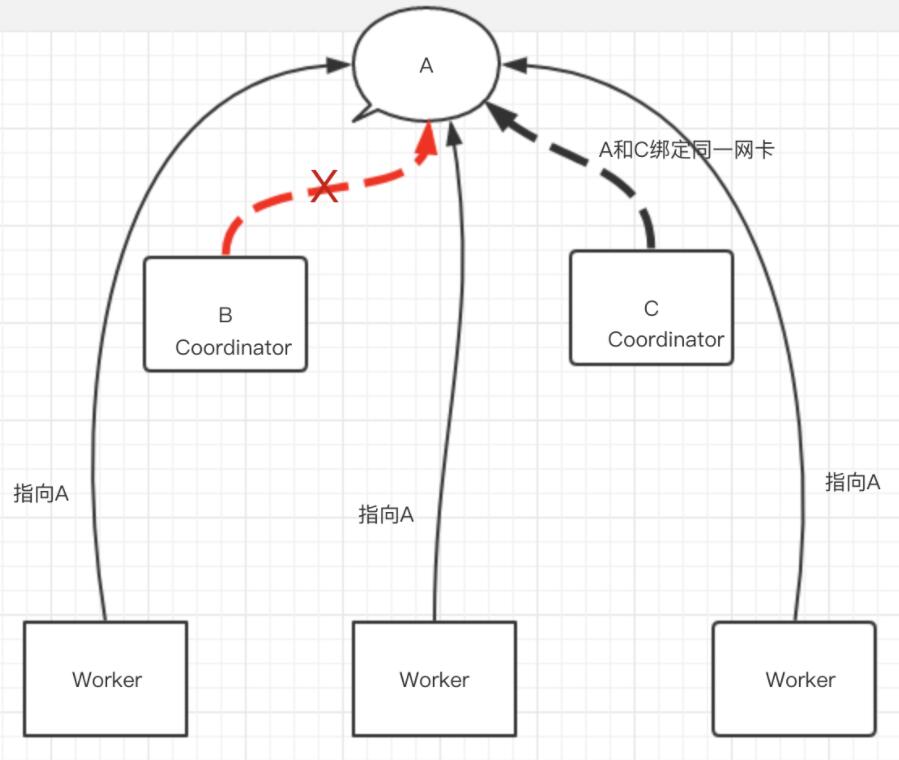
查询流程
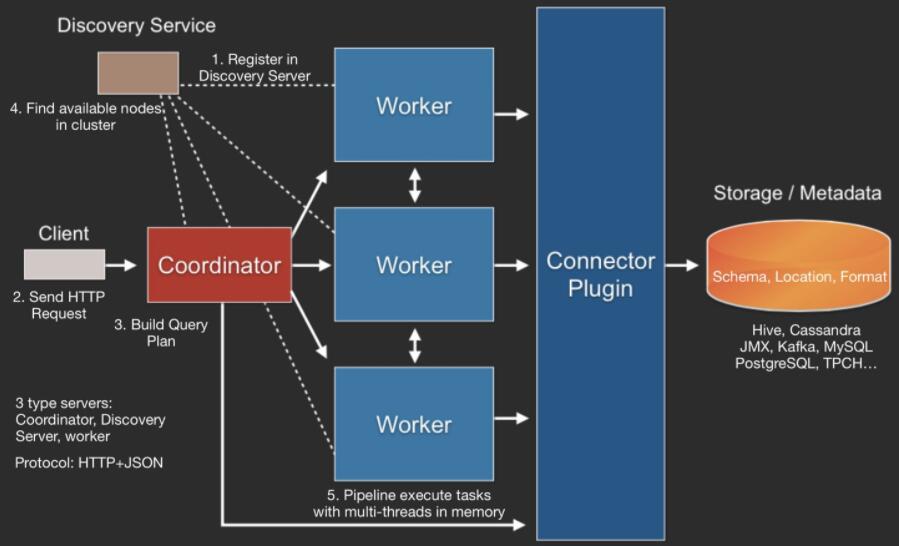
整体查询流程为
- Client使用HTTP协议发送一个query请求。
- 通过Discovery Server发现可用的Server。
- Coordinator构建查询计划(Connector插件提供Metadata)
- Coordinator向workers发送任务
- Worker通过Connector插件读取数据
- Worker在内存里执行任务(Worker是纯内存型计算引擎)
- Worker将数据返回给Coordinator,之后再Response Client
SQL执行流程
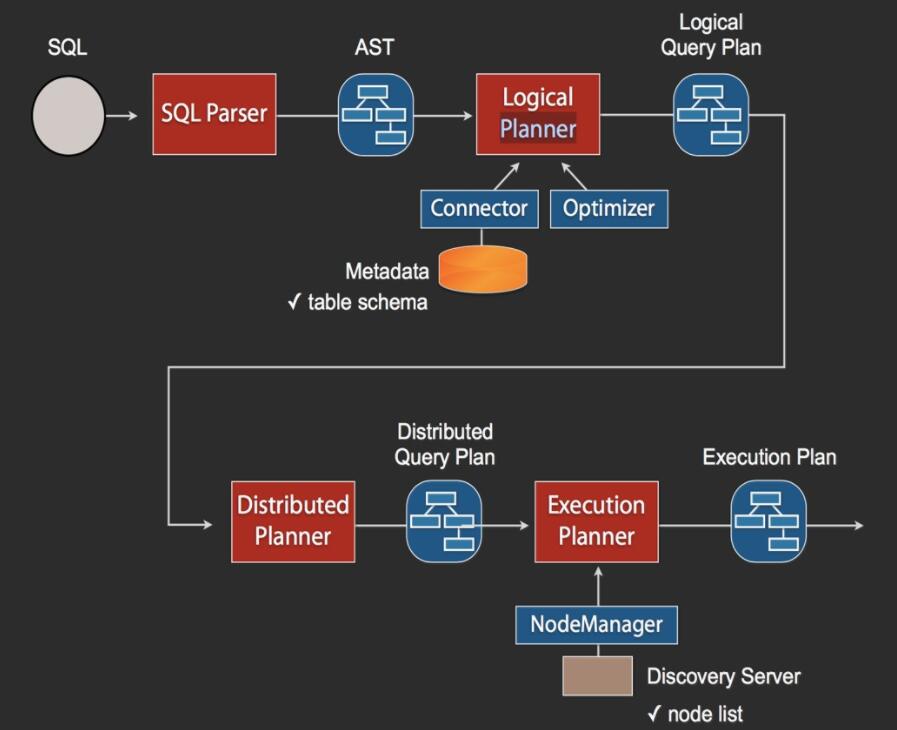
当Coordinator收到一个Query,其SQL执行流程如上图所示。SQL通过Anltr3解析为AST(抽象语法树),然后通过Connector获取原始数据的Metadata信息,这里会有一些优化,比如缓存Metadata信息等,根据Metadata信息生成逻辑计划,然后会依次生成分发计划和执行计划,在执行计划里需要去Discovery里获取可用的node列表,然后根据一定的策略,将这些计划分发到指定的Worker机器上,Worker机器再分别执行。
与Hive比较
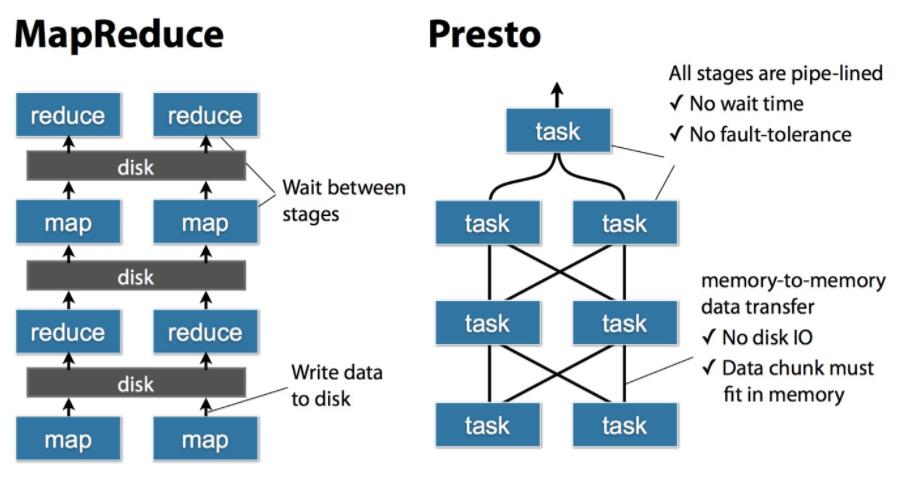
上图显示了MapReduce与Presto的执行过程的不同点,MR每个操作要么需要写磁盘,要么需要等待前一个stage全部完成才开始执行,而Presto将SQL转换为多个stage,每个stage又由多个tasks执行,每个tasks又将分为多个split。所有的task是并行的方式进行允许,stage之间数据是以pipeline形式流式的执行,数据之间的传输也是通过网络以Memory-to-Memory的形式进行,没有磁盘io操作。这也是Presto性能比Hive快很多倍的决定性原因。
实现低延时的原理
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- 类BlinkDB的近似查询
- GC控制
当然其优化方法也包括了一些传统的SQL优化原理,关于这些优化细节等后续文章详细介绍。
缺点
前面介绍了Presto的各种优点,其实其也有一些缺点,主要缺点为以下三条:
- No fault tolerance;当一个Query分发到多个Worker去执行时,当有一个Worker因为各种原因查询失败,那么Master会感知到,整个Query也就查询失败了,而Presto并没有重试机制,所以需要用户方实现重试机制。
- Memory Limitations for aggregations, huge joins;比如多表join需要很大的内存,由于Presto是纯内存计算,所以当内存不够时,Presto并不会将结果dump到磁盘上,所以查询也就失败了,但最新版本的Presto已支持写磁盘操作,这个待后续测试和调研。
- MPP(Massively Parallel Processing )架构;这个并不能说其是一个缺点,因为MPP架构就是解决大量数据分析而产生的,但是其缺点也很明显,假如我们访问的是Hive数据源,如果其中一台Worke由于load问题,数据处理很慢,那么整个查询都会受到影响,因为上游需要等待上游结果。
这篇文章就先介绍这里吧,后续会陆续更新一系列Presto相关的文章,欢迎关注。