背景 地图POI搜索业务使用的Elasticsearch集群是自建的2.3版本,维护ES需要耗费很多精力和人力。而目前公司有专门的ES搜索团队,且ES版本已经升级到7.6版本。ES 7.6版本有很多新的特性,如IndexSorting,查询加速,索引off-heap,全新的熔断器等等。6月份,ES搜索团队决定与地图POI合作共建,将ES升级到公司里的ES 7.6,专业的人做专业的事,ES团队维护集群稳定性、提升性能等,这样地图POI团队可以更好的聚焦到业务架构和推荐系统中台化上。
地图POI分为国内POI和国际化POI,其面向在线搜索业务,对搜索耗时要求比较高,国内POI要求TP50耗时小于5ms,TP99 耗时小于20ms,国际化POI要求TP50耗时小于5ms,TP99耗时小于60ms。且两个业务方的索引查询超时时间都为180ms。由于其业务特点,所以在迁移ES 7.6时,并非一帆风顺,遇到很多性能和稳定性问题,这篇文章会介绍下遇到的性能问题和解决方法。由于篇幅有限,本文只介绍了影响性能最大的三个问题及优化手段和排查问题过程,分别为:
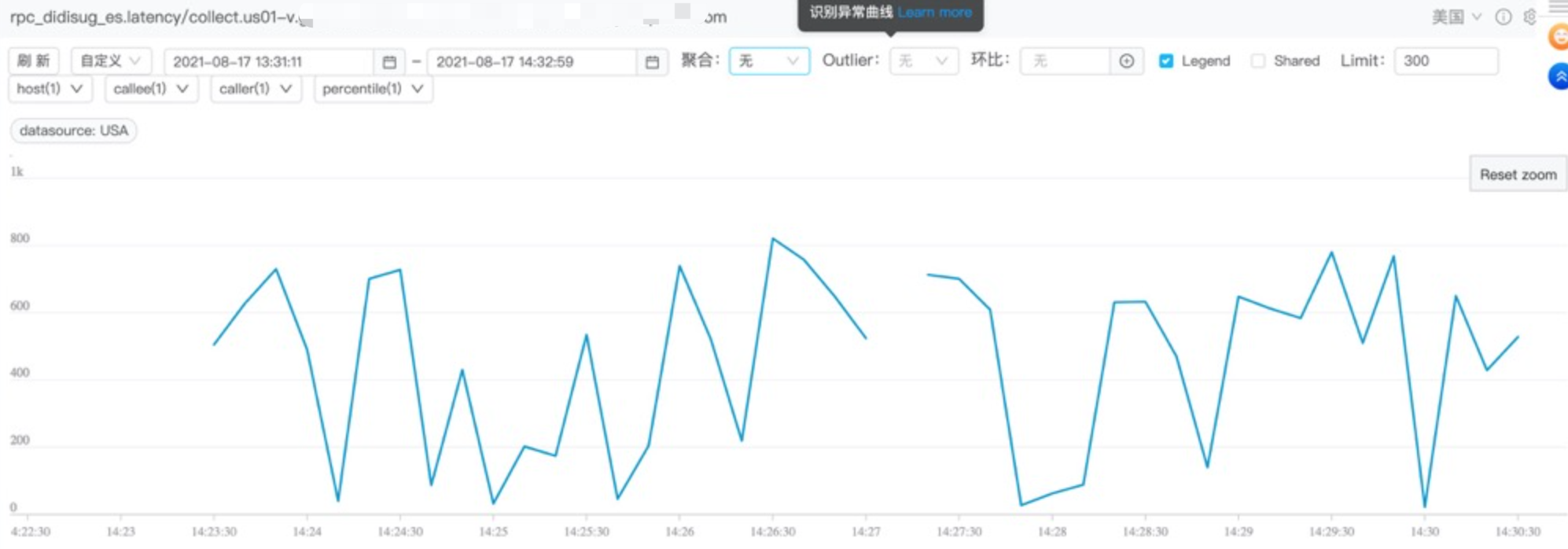
前缀查询优化 调好合适的分片数,之后将索引从Hive离线导入到ES,做一轮压测,耗时曲线图如下图所示,耗时都接近800ms了,并且超过180ms就认为是超时,这与期望的性能有比较大的差距:
通过gateway里面的审计日志,计算出国际化POI TP50、TP90、TP99时间,如下图所示:
可以看到TP99时间到了619ms,这与预期的性能有很大差距。所以我们需要看下为什么查询性能这么慢,我们将审计日志里面的压测DSL全部拿到,之后根据查询耗时降序排序,然后将DSL模板归类,发现耗时最久的是类似下面这种DSL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 GET poi_index/_search { "_source" : { "includes" : [ "city" ] }, "from" : 0 , "query" : { "bool" : { "must" : [ { "term" : { "area" : 55000199 } }, { "bool" : { "should" : { "bool" : { "boost" : 1 , "should" : [ { "prefix" : { "displayname_nor_pt.prefix" : "r" } }, { "prefix" : { "alias_pt.prefix" : "r" } }, { "prefix" : { "atlas_name_nor.prefix" : "r" } }, { "match" : { "displayname_nor_pt.invert" : { "operator" : "and" , "query" : "r" } } }, { "match" : { "atlas_address_nor.invert" : { "operator" : "and" , "query" : "r" } } } ] } } } } ] } }, "size" : 20 , "timeout" : "180ms" }
通过Kibana查询,查询耗时稳定如下:
1 2 3 4 5 6 7 8 9 10 { "took" : 1508, "timed_out" : true , "_shards" : { "total" : 10, "successful" : 10, "skipped" : 0, "failed" : 0 } }
那怎么判断这个DSL耗时浪费在哪里了呢?答案是:二分法。通过二分法删除查询语句,之后我们看到是prefix 前缀查询导致性能变慢。再讲前缀优化之前,先说下为什么前缀查询慢,比如我们将上面的DSL简化为:
1 2 3 4 5 6 7 8 GET my_index/_search{ "query" : { "prefix" : { "displayname_nor_pt.prefix" : "r" } } }
上面的查询,为了支持前缀匹配,查询会做以下事情:
扫描词列表并查找到第一个以 r 开始的词
搜集关联的文档ID
移动到下一个词
如果这个词也是以 r 开头,查询跳回到第二步再重复执行,直到下一个词不以 r 为止
这对于小的例子当然可以正常工作,但是如果倒排索引中有数以百万的 displayname_nor_pt.prefix 都是以 r 开头时,前缀查询则需要访问每个词然后计算结果。且前缀越短所需访问的词越多。那如何优化呢?答案是:Edge NGram。以单词hello为例,Edge NGram Token Filter设置下min_gram为1,max_gram为5。它的Edge NGram的结果如下:
其意思就是在使用Edge NGram建索引时,一个单词会生成多个倒排索引,比如hello,将生成5个倒排,核心思想就是空间换时间,将前缀匹配转换为term查询。但是使用Edge NGram用户需要修改查询语句,为了提高用户体验,减少升级工作量,发现ES 7.X 支持了 index_prefixes,在创建mapping时指定,我们将业务索引模板mapping添加类似如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 "properties" : { "displayname_nor_pt" : { "type" : "keyword ", " fields" : { " prefix" : { " index_prefixes" : { " max_chars" : 7, " min_chars" : 1 }, " analyzer" : " keyword_lower", " type " : " text" } } } }
之后重新导入数据,相同的查询,耗时变为:
1 2 3 4 5 6 7 8 9 10 { "took" : 3, "timed_out" : false , "_shards" : { "total" : 10, "successful" : 10, "skipped" : 0, "failed" : 0 } }
性能提升500倍+,之后再压测,查看国际化POI TP50 TP99耗时:
查询截断 优化Prefix后,国际化POI TP99耗时到了81ms,但是我跟POI业务方保证能优化到50ms以内,目前离目标还有距离,所以继续分析国际化的DSL,发现查询语句里大部分是没有使用terminate_after截断,少部分使用截断功能的DSL,截断值是200000,而其查询size一般为15。先解释下terminate_after:
1 terminate_after: 限定从每个shard中收集的最大文档数量。缺省不设此最大数量限制。如果设定了该值,那么响应结果中将会包含一个terminated_early的字段,以表示该次查询实际上是较早地终止了。
根据上面的定义,如果直接使用terminate_afer,那会导致严重diff,如果为了解决这个问题:
IndexSorting,指定字段做预排序,查询时候sort
索引完成导入时,调用force merge,每个分片生成一个segment
在做了预排,召回的size如果只需要15个的话,查询DSL里添加terminate_after=15,这样可以大量减轻节点的排序截断的内存消耗和计算量。POI团队优化DSL后查询性能,TP99从81ms降低到41ms:
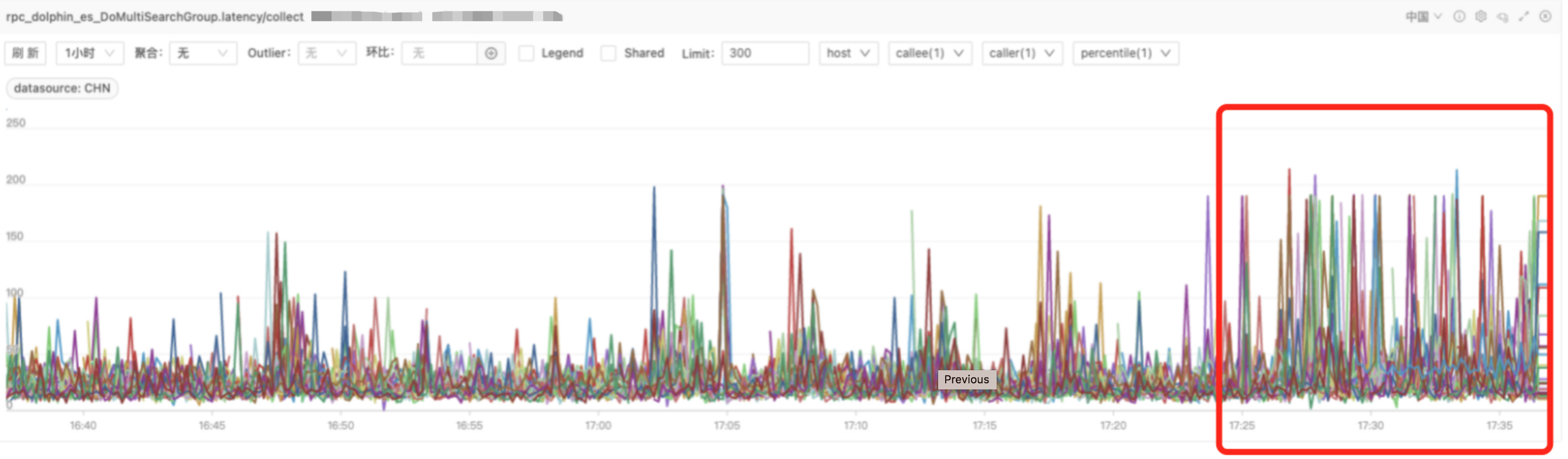
查询超时毛刺 国内POI升级到7.6后,遇到个非常奇怪的问题,机器CPU使用率5%不到,但是会有接近5%的查询会超时,但是如果单独查询时,就不会超时,意思是查询不稳定。如下图所示,17:25流量请求到7.6集群,然后就会出现大量查询超时(超过180ms),且重复执行时候,又不出现超时了。
这个问题比较棘手,排查了ES引擎,dmesg,内存、CPU及IO等等都没有出现瓶颈。根据我的经验,可能是page fault导致的,或者遇到CPU false sharing问题或者Cache line导致的性能下降问题,因为ES需要从磁盘读取索引,Page Cache导致的问题概率更高。随手去perf stat看下机器情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Performance counter stats for 'system wide': 16425927 .374625 task-clock (msec) # 95 .999 CPUs utilized 16 ,344 ,280 context-switches # 0 .995 K/sec 220 ,755 cpu-migrations # 0 .013 K/sec 6 ,860 ,133 page-faults # 0 .418 K/sec 39 ,43 ,737 ,586 ,430 cycles # 2 .400 GHz 4 ,388 ,353 ,876 ,624 instructions # 0 .11 insn per cycle 992 ,167 ,860 ,072 branches # 60 .403 M/sec 3 ,670 ,316 ,256 branch-misses # 0 .37 % of all branches 171 .104416655 seconds time elapsed
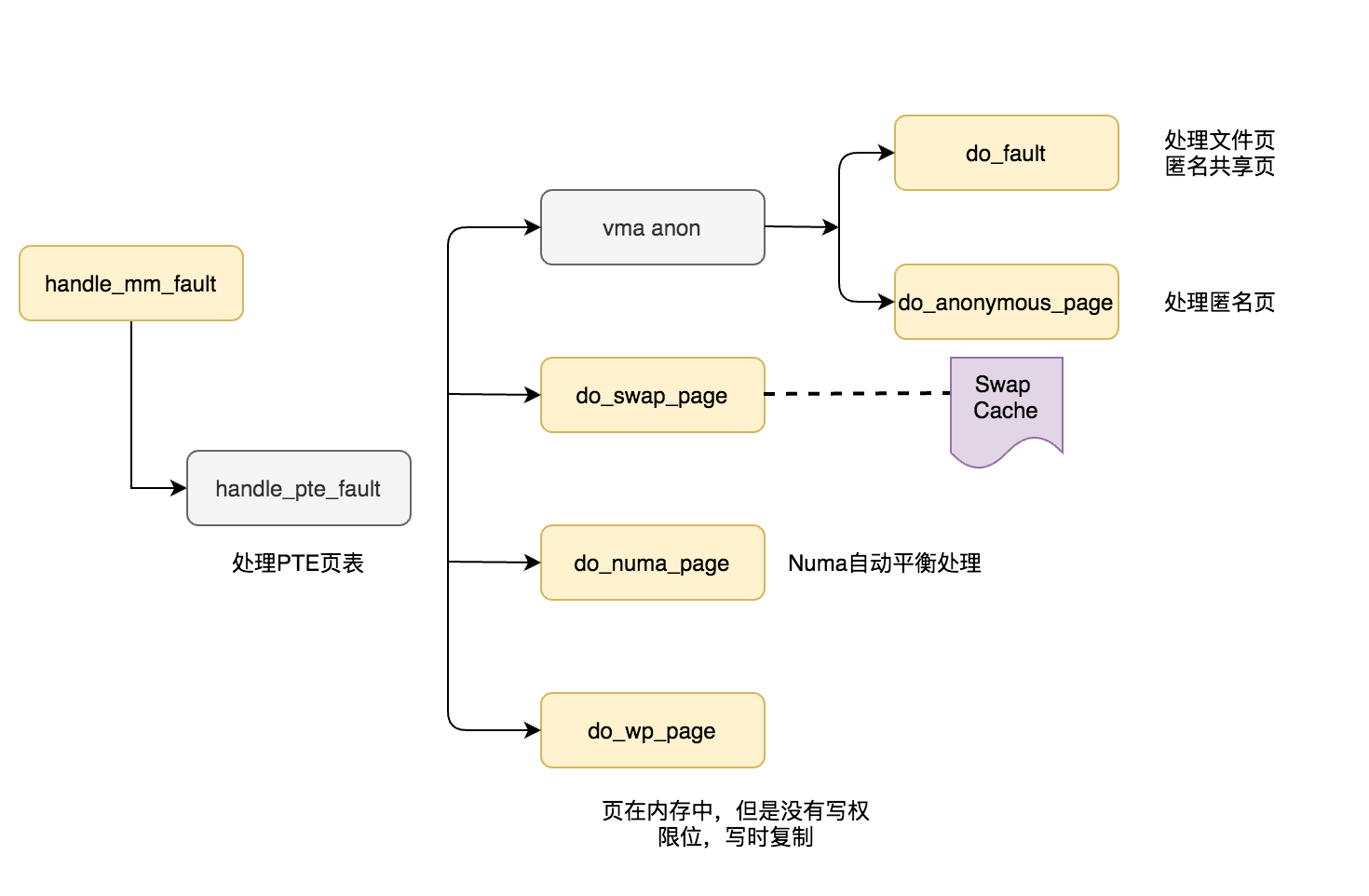
于是我又对比了查询正常的集群,perf数据对比后发现context-switches及page-faults有些偏高,我想确认下page-faults耗时及是哪个函数(功能)耗时久,有时候想知道下发某个操作后内核在做些什么,这个时候就要对内核进行调试,我们可以使用kprobe来探测内核的行为。在使用kprobe hook内存前,我们需要先知道page fault相关的函数,这个函数是handle_mm_fault,进程在用户态及内核态访问虚拟地址,触发缺页异常,用于处理用户空间的页错误异常,这个函数下面可以被hook的函数如下(黄色背景):
回到问题上,我们需要确认是page fault导致的问题,我们首先需要看下handle_mm_fault函数申请耗时,方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #include <linux/kernel.h> #include <linux/module.h> #include <linux/kprobes.h> #include <linux/ktime.h> #include <linux/limits.h> #include <linux/sched.h> #include <linux/cgroup.h> #include <linux/dcache.h> #include <linux/aio.h> static char func_name[NAME_MAX] = "handle_mm_fault" ;module_param_string (func, func_name, NAME_MAX, S_IRUGO);MODULE_PARM_DESC (func, "Function to kretprobe; this module will report the" " function's execution time" ); struct my_data { ktime_t entry_stamp; int printk; struct bdi_writeback *wb; }; static int entry_handler (struct kretprobe_instance *ri, struct pt_regs *regs) struct my_data *data; data = (struct my_data *)ri->data; data->printk = 1 ; data->entry_stamp = ktime_get (); return 0 ; } static int ret_handler (struct kretprobe_instance *ri, struct pt_regs *regs) long retval = regs_return_value (regs); struct my_data *data = (struct my_data *)ri->data; s64 delta; ktime_t now; now = ktime_get (); delta = ktime_to_ns (ktime_sub (now, data->entry_stamp)); if (!data->printk) { return 0 ; } if (delta / 1000 / 1000 > 100 ) printk ("pid %ld, %s in %s returned %d and took %lld ns to execute\n" , current->pid, current->comm, func_name, retval, (long long )delta); return 0 ; } static struct kretprobe my_kretprobe = { .handler = ret_handler, .entry_handler = entry_handler, .data_size = sizeof (struct my_data), .maxactive = 1024 , }; static int __init kretprobe_init (void ) int ret; my_kretprobe.kp.symbol_name = func_name; ret = register_kretprobe (&my_kretprobe); if (ret < 0 ) { printk (KERN_INFO "register_kretprobe failed, returned %d\n" , ret); return -1 ; } printk (KERN_INFO "Planted return probe at %s: %p\n" , my_kretprobe.kp.symbol_name, my_kretprobe.kp.addr); return 0 ; } static void __exit kretprobe_exit (void ) unregister_kretprobe (&my_kretprobe); printk (KERN_INFO "kretprobe at %p unregistered\n" , my_kretprobe.kp.addr); printk (KERN_INFO "Missed probing %d instances of %s\n" , my_kretprobe.nmissed, my_kretprobe.kp.symbol_name); } module_init (kretprobe_init)module_exit (kretprobe_exit)MODULE_LICENSE ("GPL" );
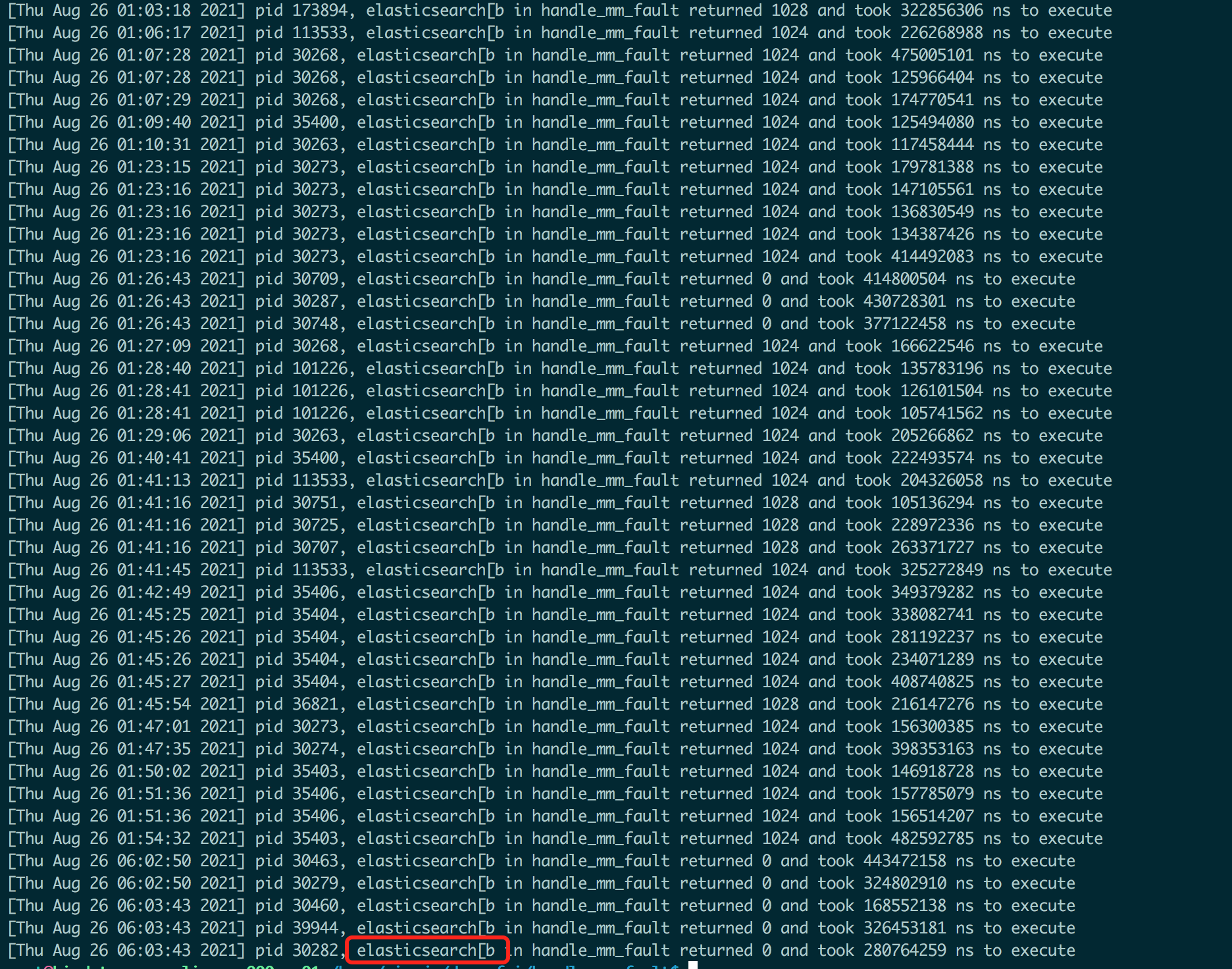
上面的代码简单解释下,抓取内核缺页耗时(handle_mm_fault),超过100ms就打印进程id(JVM里是线程id)及进程名。关于kprobe,可以详细看下这个wiki:kprobe kretprobe example 。之后编译,通过 insmod *ko 加载到内核模块,通过dmesg静等结果,第二天早晨dmesg看下,看到如下信息:
可以看到确实缺页函数执行超过100ms,符合之前猜想。为了更精确判断哪个函数导致的,我们一次跟踪了do_wp_page、do_numa_page等,发现耗时主要是do_numa_page导致的问题。numa为啥会导致性能问题呢?关于APAR IT23357对性能影响的更深层次探讨
看了下机器numa状态:
1 2 3 4 5 6 7 8 9 10 11 node0 node1 numa_hit 18920313219 16185022530 numa_miss 858944103 1083697842 numa_foreign 1083697842 858944103 interleave_hit 109322 109638 local_node 18923181605 16191147877 other_node 856075717 1077572495
有2个node,numa balancing就是提供一个numa自动平衡策略,系统通过自动调配内存以求在各个numa nodes的内存使用率处于相对平衡的状态,这个策略可以通过修改内核参数/proc/sys/kernel/numa_balancing控制。所以尝试关闭了下numa balancing,命令如下:
1 # echo 0 > /proc/sys/kernel/numa_balancing
查询超时毛刺奇迹般的消失了。
总结 由于篇幅有限,抛砖引玉讲了支持毫秒级搜索业务遇到的三个性能问题,然而为了支持好这种毫秒级线上业务,仅仅做这些是不够的,双方团队相互合作,一起做了召回diff、双活(Master Slave)支持和演练、force merge以及做了SOP预案等等。后续可能需要更多精力来维护集群稳定性,查询长尾问题以及通过更好的了解业务来优化引擎和提升体验。