带团队几年后,很容易快速判断一个同学是否靠谱。那什么是靠谱?即你把一个事情交给一个人后,完全不用操心后续,因为你知道他肯定能落实,就算中间有困难,他也会及时给与你反馈,然后一起协商后续应该如何快速解决此问题。如果靠谱度需要分级的话,我会将其分为三层:做完、做好、做到极致。但是靠谱度是可以培养的,我认为做好以下几点就基本可以胜出了。
1、能拿结果
即做事情要站在结果的角度去考虑和解决问题,以终为始,从目标开始考虑需要什么条件,然后主动想办法去创造条件从而达成问题的解决。但是不要把“过程导向”和“结果导向”对立起来二选一,实际上在职场中,结果导向并不意味着不重视过程,恰恰相反,而是要用以终为始的心态,带着清晰的目标,善用3W分析法,去开启和推进做事情的过程。
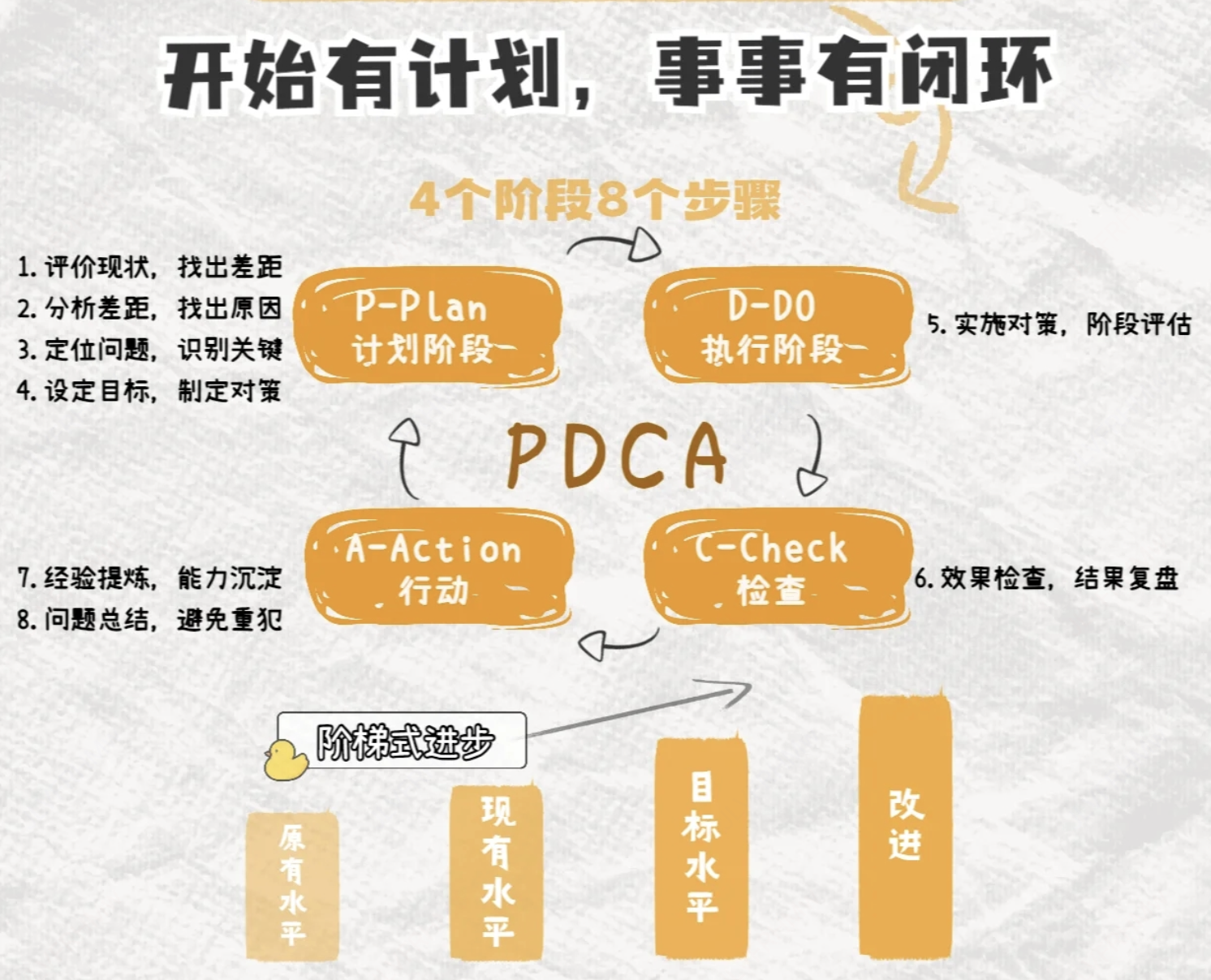
2、具备闭环思维
简单来说就是“凡事有计划,约定必落实,问题早知会,及时报进程,事后须反馈”。闭环思维的培养需要多使用PDCA法则指导自己。