喊了几天学习Web开发,为了毕业论文,今晚上计划也是看看CSS呢,但是实在是没忍住,读了下经典的tinyhttp的源代码,这款代码还是颇有名气的,网上这么评论的:
tinyhttpd是一个超轻量型Http Server,使用C语言开发,全部代码只有500、600行,附带一个简单的Client,可以通过阅读这段代码理解一个Http Server的本质。
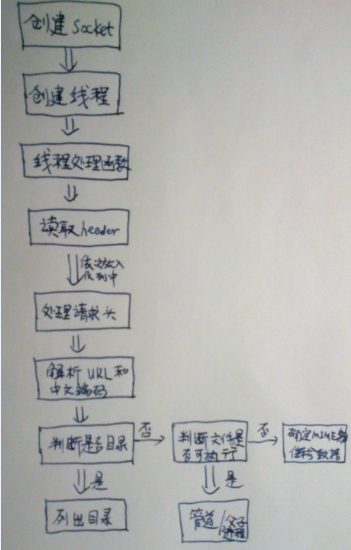
其实,代码颇简单,适合刚学习Web Server的童鞋学习,因为我之前写过CGI Server,所以,我还是认为此代码写的一般,并且我在Ubuntu下编译遇到了不少错误,我都懒得写详细分析了,所以随便写下吧,后面的Github地址里有详细的分析。